大语言模型训练原理与实践(一): BPE分词算法
上一篇文章中,我们已经了解了大语言模型通过在海量自然语言语料上学习预测下一个 token,以此建立语言理解能力,这一过程也就是所谓的预训练。那么问题随之而来:我们经常提到的token究竟是什么?它与文本、词汇之间有着怎样的关系与区别?
为了解决这个问题,我们需要从文本如何被编码成模型可读的序列说起。
早期的编码方案
字符级编码
以英文为例,在早期的文本编码方案中,每个字符都被单独视为一个token,这也被称为字符级编码。例如,对于句子:”hello world!”,它的token序列(尚未映射为数字)为:['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!']。
这种编码方式的优点十分明显:实现简单、通用性(可扩展性)强,词表较小,可以处理几乎所有语言中的所有字符,不会存在OOV(Out-Of- Vocabulary)问题。然而,它也存在显著的局限性:
- 由于每个字符都被单独编码,序列长度显著增加,模型在处理长文本时计算开销大,训练效率低。
- 字符粒度太细,模型难以捕捉词语层面的语义结构——试问有谁是按字符理解语言的?

词级编码
相比字符级编码,词级编码以「词(word)」作为基本单位,将每个词直接映射为一个 token。这是人类语言理解的自然粒度,因此这种编码方案在早期 NLP 模型中(如 Word2Vec、LSTM)被广泛采用。
同样对于句子:”hello world!”,采用词级编码得到的token序列为: ['hello', 'world', '!']。
这种编码方式的优点在于:
- 直观,与人类语言习惯一致,每个token具有完整的语义信息。
- 编码序列短,处理效率高。
但这种编码方式也存在缺点:
每个词都得编码成一个token,导致词表庞大。
Many people estimate that there are more than a million words in the English language. In fact, during a project looking at words in digitised books, researchers from Harvard University and Google in 2010, they estimated a total of 1,022,000 words and that the number would grow by several thousand each year.
词表虽然变大了,但出现未登录词的可能性反而上升了:一旦有什么新的单词没收录在表里,模型只能以
<unk>代替,导致信息损失严重。跨语言迁移能力较差。
我们可以看到,前述的两种分词编码方法要么粒度太细,模型读不懂语义;要么粒度太粗,新词一来就懵逼,只能用 <unk> 顶上。可见这两种方式都不太理想。
为了取得两者的平衡,让模型在表达能力与编码效率之间取得更好的平衡,子词级编码方法被提出。这类方法试图将文本划分为比「词」更小、但比「字符」更有语义的信息单元,从而兼顾词汇覆盖率与建模能力。其中最具代表性、也是目前应用最广泛的方案,就是BPE(Byte Pair Encoding)算法。
BPE 算法
如前文提到的,在自然语言处理中,研究者经常会面临两个极端:
下策:以字符为编码单位,不容易OOV,但缺点过于致命:模型完全不知道这些字符合起来是什么意思,学习难度过大。
上策:以词为编码编码单位,可以保留完整的语义信息,例如:
internationalization这个词整体作为一个token,语义信息丰富,看上去省事省心一步到位。然而,问题来了——如果是internationalizations呢?多了个 s,抱歉,模型词典里没有,不认识。由此可见,词级编码面临一个大bug:词表巨大、组合爆炸、扩展性差。你得穷尽所有单词的各种变形、拼写版本……搞得像字典编辑部天天加班。

于是,一种「花下策的成本,达到上策的效果」的中策应运而生:BPE算法。(当然,实际上成本肯定是要高于下策的,但性价比已经相当高了)
其实这个算法很早就已经被提出了,当时是用于数据压缩,其基本思路是通过寻找文本中出现频率最高的相邻字节对,将其合并为一个新的字节,然后重复该操作直到达成某种终止条件。
本文略过该算法在数据压缩领域的应用,直接介绍如何将这种思路用于tokenizer。
算法流程概览
偷懒了,这里直接放个训练过程的伪代码。
至于训练结束后如何进行分词,主要就是用了上面算法输出的合并规则序列 ,分词过程的基本思路是:
先将输入文本按照最细粒度(如字符级)进行切分,然后依照 $\mathcal{M}$ 中的合并顺序,从上到下依次遍历并执行匹配合并操作,直到无法再匹配为止。
实例演示
以一个简单的语料集为例,假设我们拿到了数据:
low lower lowest
play played playing player
happy happier happiest
running runs runner
international internationalization internationalize
understanding misunderstand misunderstanding我们首先拿到所有单词按字符的拆分,同时在末尾添加一个符号</w>表示词尾:
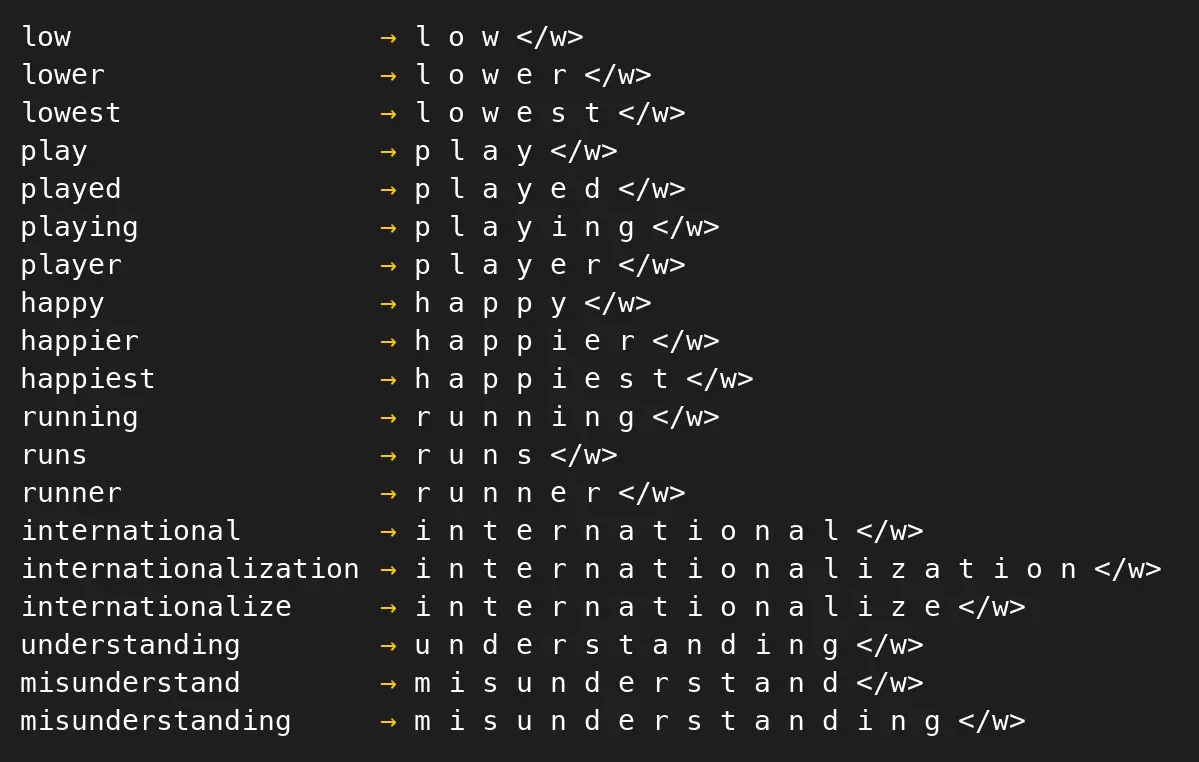
将所有出现过的字符记录下来,作为当前的词表(词表大小为19):
{'w', 'r', 'e', 'u', 'a', 't', 'i', 'z', 'n', 'y', 'm', '</w>', 'd', 'g', 'h', 'p', 'l', 's', 'o'}假设我们的目标词表长度为25。
我们统计每一对相邻字符出现的频率,并按频率从高到低排序,我们得到相邻字符对的频率表(省略了后面的部分):
('e', 'r'): 10
('i', 'n'): 7
('u', 'n'): 6
('n', 'a'): 6
('n', 'd'): 6
('s', 't'): 5
('r', '</w>'): 4
...找到出现频率最高的组合:('e', 'r'),然后遍历所有拆分列表,将所有该组合进行合并,得到新的单词拆分方式:
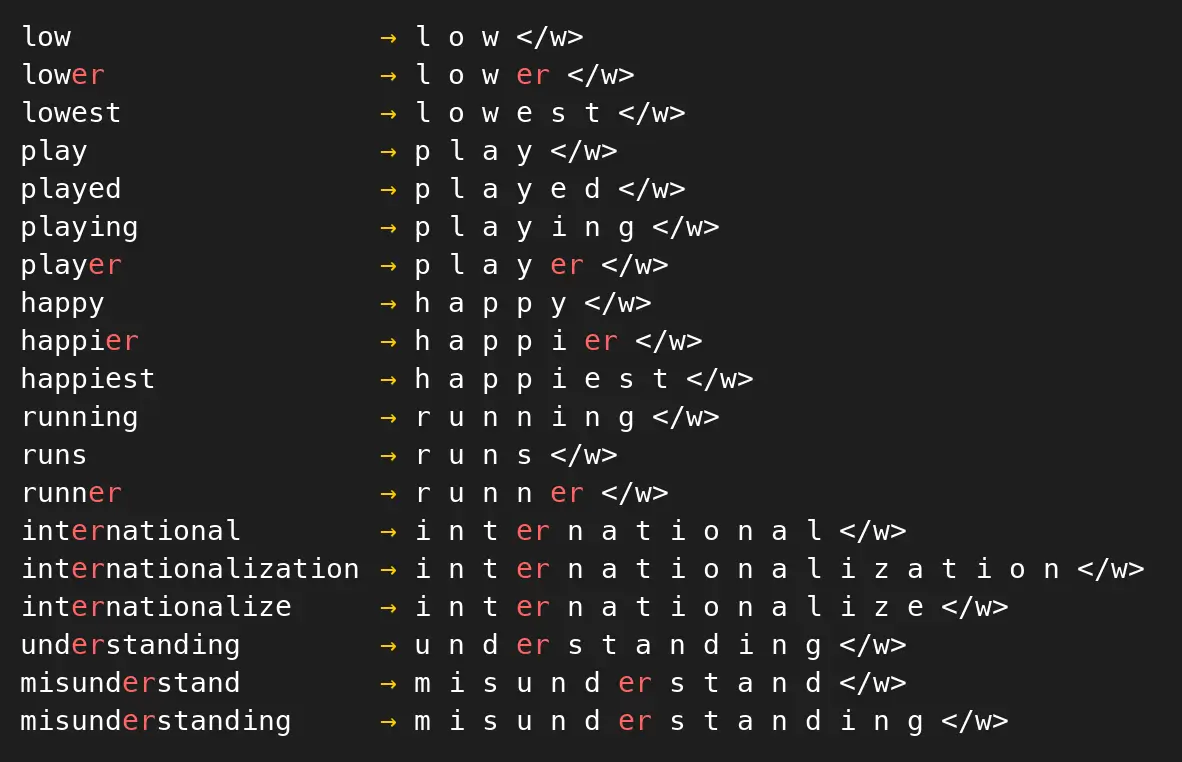
将组合er添加到词表中,不过此时单词的拆分中仍存在独立的e和r,故将它们保留在词表中。当前词表大小:20。
继续统计每一对相邻字符(此时,由于我们前面合并了e和r,故在统计时需要把er看作一个整体)。我们得到新的相邻字符对的频率表:
('i', 'n'): 7
('u', 'n'): 6
('n', 'a'): 6
('n', 'd'): 6
('s', 't'): 5
('er', '</w>'): 4
...合并i与n,将in加入词表,不移除i和n。当前词表大小:21。
统计新的相邻字符频率:
('u', 'n'): 6
('n', 'a'): 6
('n', 'd'): 6
('s', 't'): 5
('er', '</w>'): 4
...合并u与n,将un加入词表:
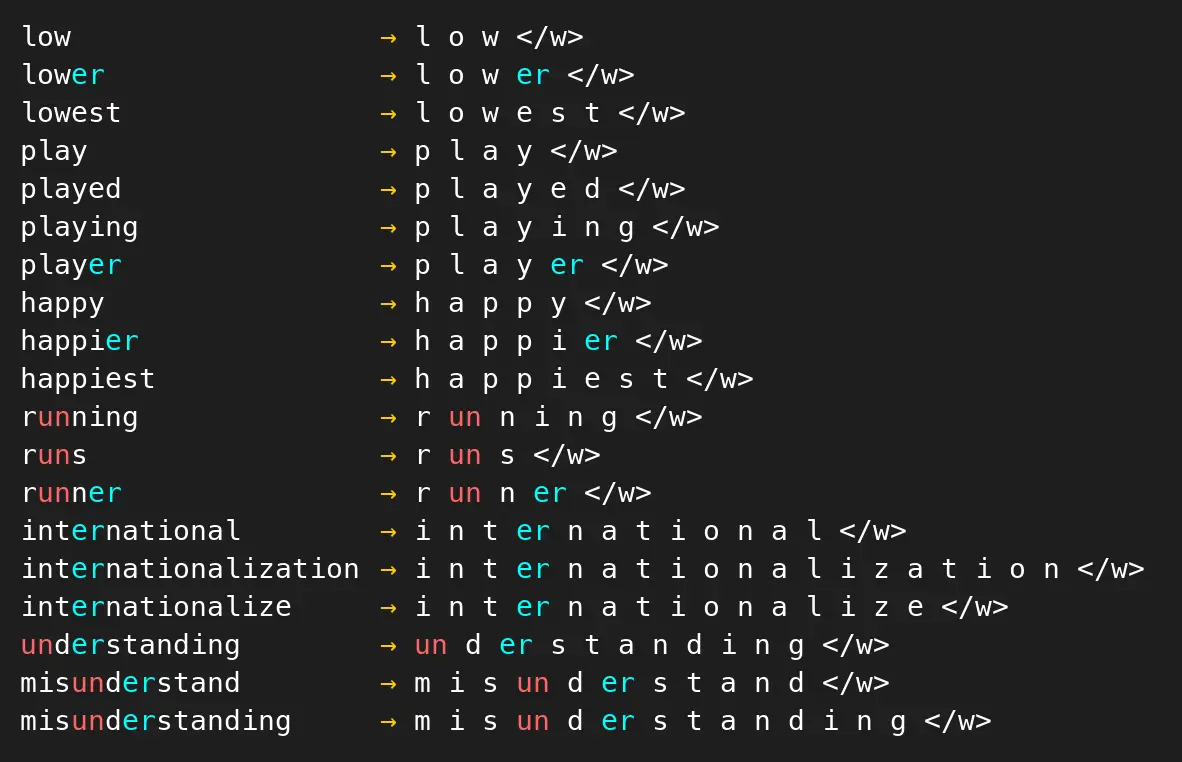
此时,发现已经没有单独出现的字符u了,因此从词表中移除u。当前词表大小:21。
持续进行上述操作,直到达到下面两个终止条件之一:
- 词表大小达到我们的预设值:本例中为25。
- 没有可合并的高频相邻字符对。(可自定义频率阈值)
代码
from collections import defaultdict
corpus = [
'low lower lowest',
'play played playing player',
'happy happier happiest',
'running runs runner',
'international internationalization internationalize',
'understanding misunderstand misunderstanding'
]
class BPE:
def __init__(self, corpus, vocab_size):
self.corpus = corpus
self.vocab_size = vocab_size
self.alphabet = {'</w>'}
self.word_freqs = defaultdict(int)
self.split = {}
self.merges = {}
self.initialize()
self.vocab = self.alphabet.copy()
def initialize(self):
for words in self.corpus:
for word in words.split(' '):
self.word_freqs[word] += 1
self.alphabet.update(set(word))
self.split = {word: list(word) + ['</w>'] for word in self.word_freqs.keys()}
def print_split(self):
max_len = max(len(word) for word in self.split)
for word, s in self.split.items():
padding = " " * (max_len - len(word))
print(f"{word}{padding} → {' '.join(s)}")
def get_stats(self):
pairs = defaultdict(int)
for word, freq in self.word_freqs.items():
word_split = self.split[word]
for i in range(len(word_split) - 1):
pairs[(word_split[i], word_split[i + 1])] += freq
return pairs
def merge_pair(self, pair):
self.merges[pair] = ''.join(pair)
for word in self.word_freqs:
split = self.split[word]
if len(split) == 1:
continue
idx = 0
while idx < len(split) - 1:
if (split[idx], split[idx + 1]) == pair:
split[idx] = ''.join(pair)
del split[idx + 1]
else:
idx += 1
def find_single_item(self, item):
for split in self.split.values():
for i in split:
if i == item:
return True
return False
def train(self):
while len(self.vocab) < self.vocab_size:
pairs = self.get_stats()
if not pairs:
break
sorted_pairs = sorted(pairs.items(), key=lambda x: x[1], reverse=True)
max_pair, max_freq = sorted_pairs[0]
if max_freq <= 1:
break
self.merge_pair(max_pair)
self.vocab.add(''.join(max_pair))
for i in max_pair:
if not self.find_single_item(i):
self.vocab.remove(i)
print("Vocab size: ", len(self.vocab), end='\r')
def tokenize(self, text):
pre_tokenized_text = text.split(' ')
splits_text = [[_ for _ in word] for word in pre_tokenized_text]
for pair in self.merges.keys():
for split in splits_text:
idx = 0
while idx < len(split) - 1:
if (split[idx], split[idx + 1]) == pair:
split[idx] = ''.join(pair)
del split[idx + 1]
else:
idx += 1
result = sum(splits_text, [])
return result
def export_vocab(self, vocab_path="vocab.json"):
vocab = {token: idx for idx, token in enumerate(self.vocab)}
import json
with open(vocab_path, "w", encoding="utf-8") as f:
json.dump(vocab, f, ensure_ascii=False, indent=2)
print(f"Saved vocab to {vocab_path}")
def export_merges(self, merges_path="merges.txt"):
with open(merges_path, "w", encoding="utf-8") as f:
f.write("#version: 0.2\n")
for pair in self.merges.keys():
f.write(f"{pair[0]} {pair[1]}\n")
print(f"Saved merges to {merges_path}")
bpe = BPE(corpus, 25)
bpe.train()
以上便是 BPE(Byte Pair Encoding)分词算法的核心思想、训练流程与示例代码。它以字符为起点,通过词频驱动的逐步合并,构建出稳定、高效、具有语义结构的子词单元,从而有效缓解了 OOV 问题并保证了模型的语义建模能力。
如今,随着自然语言处理技术的进一步发展,已经出现了许多更先进的分词技术,如基于概率的 Unigram 模型等,但 BPE 仍然是理解现代分词算法原理的良好起点。它结构清晰、逻辑直观,能够帮助我们把握子词构建、词表学习与编码压缩等核心思想,为进一步理解更复杂的分词方法打下基础。
有了分词器,我们便能将原始的自然语言文本转化为模型可以处理的 token 序列,搭建起语言与模型之间的桥梁。在此基础上,模型在大规模语料上进行预训练才成为可能。但这一步,只是让模型学会“怎么说话”。
经过了充分预训练的语言模型,只是一个“话痨”——它能接得住任何话题(擅长续写),却不一定听得懂你的意思。要让它从“能说”变成“听话”,我们还需要通过监督微调(SFT)进一步训练,让模型学会听指令、做任务、少废话。
这就是大模型训练的第二块拼图——笔者将在下一篇文章中进行讨论。
 V me 50!
V me 50!- Alipay is also ok~


