大语言模型训练原理与实践(二):监督微调(SFT)
在前两篇文章中,博主已经简单介绍了大语言模型的预训练阶段,以及如何通过BPE(Byte Pair Encoding)算法将自然语言高效地转化为离散的子词单元,从而降低词表规模、提高模型泛化能力。
我们已经知道,在大规模语料数据上进行的预训练使模型具备了广泛的语言知识,但它学到的仅仅是“如何预测下一个词”的通用能力,距离解决特定任务(如问答、摘要、对话)还有相当的差距。
而监督微调正是让大语言模型从通用语言能力升级到任务导向能力的必经之路。换言之,SFT让模型不仅仅局限于能够把话写通顺,还能写的对题。
另外,博主基于一款参数量约为 2.13B 的迷你大语言模型,完成了其微调流程的简要复现。相关代码已开源,详见下面链接。
通过合理配置训练参数,并结合 LoRA(Low-Rank Adaptation),整个微调训练流程可在一块消费级显卡(博主使用的是 RTX 3090 Ti)上顺利完成。

监督微调是什么
监督微调(Supervised Fine-Tuning, SFT)是指在预训练模型的基础上,利用一个特定任务的人类标注数据集对模型进行进一步训练,从而教会模型如何更好地执行具体指令或任务,例如问答、摘要、对话、翻译等。
与预训练阶段在海量无标注自然语言数据集上进行训练不同,SFT 使用成对的输入-输出样本,通过显式的任务目标,引导模型“怎么按人类意图作答”。这一阶段通常只微调模型的一部分参数,例如最后几层,既能保留预训练所得的通用语言知识,又能高效适应特定任务。
数据集 & 处理方法
这一阶段的训练数据可能长这样:
{
"prompt": "请简要介绍一下蔡徐坤是谁。",
"response": "蔡徐坤是中国内地流行歌手、演员、音乐制作人,曾因参加《偶像练习生》节目而走红。"
}不过,为了适合语言模型的输入格式,这类数据通常会被拼接成统一的 prompt 模板格式,明确区分“指令”和“回答”的结构,引导模型学会角色扮演和任务对齐。例如:
Human: 请简要介绍一下蔡徐坤是谁。
Assistant: 蔡徐坤是中国内地流行歌手、演员、音乐制作人,曾因参加《偶像练习生》节目而走红。或者这种格式:
### Instruction:
请简要介绍一下蔡徐坤是谁。
### Response:
蔡徐坤是中国内地流行歌手、演员、音乐制作人,曾因参加《偶像练习生》节目而走红。在实际训练时,这些格式会被进一步编码成 token 序列,并通过 label masking 的方式只对回答部分计算损失,这是因为我们的目的是让模型学会如何输出回答部分。下面代码给了一个具体的例子:
def __getitem__(self, idx):
data = self.dataset[idx]
instruction = data['instruction']
input = data['input']
output = data['output']
if input:
prompt = f"指令:{instruction}\n{input}\n输出:"
else:
prompt = f"指令:{instruction}\n输出:"
prompt_ids = self.tokenizer.encode(prompt, add_special_tokens=False)
response_ids = self.tokenizer.encode(output, add_special_tokens=False)
input_ids = prompt_ids + [self.tokenizer.bos_token_id] + response_ids
labels = [-100] * (len(prompt_ids) + 1) + response_ids
input_ids = input_ids[:self.max_length]
labels = labels[:self.max_length]
if len(input_ids) < self.max_length:
input_ids += [self.tokenizer.eos_token_id]
labels += [self.tokenizer.eos_token_id]
pad_len = self.max_length - len(input_ids)
if pad_len > 0:
input_ids += [self.tokenizer.pad_token_id] * pad_len
labels += [-100] * pad_len
attention_mask = [1] * (self.max_length - pad_len) + [0] * pad_len
return {
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long),
"labels": torch.tensor(labels, dtype=torch.long)
}上述代码的完整版见此文件。该方法做了两件事:
- 将数据处理为
prompt_ids + bos_token_id + response_ids + eos_token_id的形式,构成完整的输入序列。 - 使用
-100为labels中的prompt部分以及pad部分打上掩码(因为这些内容模型不需要学习)。
LoRA
LoRA(Low-Rank Adaptation) 是一种轻量级参数微调方法,其核心思想是矩阵的低秩分解,具体而言,是在不改变原有大模型参数的基础上,以两个低秩矩阵的乘积的形式添加一个可学习的增量参数模块,从而达到高效微调的目的。
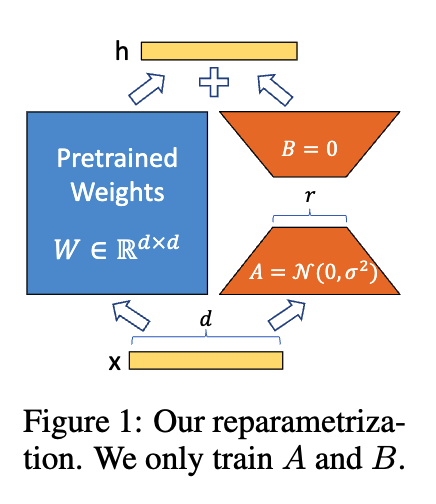
在SFT中,LoRA是一种常见的微调手段,这是因为对大模型进行全量微调不仅参数量太大、显存开销高,而且容易干扰原预训练模型(过多学习指令数据集导致模型忘记原有的语言能力),相比之下,LoRA 只在模型中插入少量可训练参数,既降低了资源需求,又避免了灾难性遗忘,使得微调过程更稳定、灵活,适合小数据集和多任务扩展场景。
LoRA 在不修改原始权重矩阵 的前提下,通过添加一个低秩矩阵近似项 来引入可学习的增量:
其中 和 是两个秩为 的矩阵。在训练时,我们冻结原始权重矩阵 ,仅学习 和 ,从而极大的减少了可学习的参数量,同时还能保证原始模型的表达能力不受过多干扰。
一个简单的LoRA层实现:
from torch.nn import Module
class LoraLinear(torch.nn.Module):
def __init__(self, linear, r=128, alpha=32):
super().__init__()
self.linear = linear
self.r = r
self.alpha = alpha
self.scale = alpha / r
self.lora_A = torch.nn.Parameter(torch.randn(linear.in_features, r) * 0.1)
self.lora_B = torch.nn.Parameter(torch.zeros(r, linear.out_features))
self.linear.weight.requires_grad = False
def forward(self, x):
y = self.linear(x)
y += self.scale * (x @ self.lora_A @ self.lora_B)
return y训练过程
在完成数据预处理和模型结构准备(如插入 LoRA 模块)后,监督微调的训练流程与预训练阶段非常类似,核心仍是语言模型的自回归目标:
其中 和 分别为用户的prompt和人类标注的参考回答。
训练流程的详细代码见此文件。
到了这里,我们已经了解了大语言模型训练中的第二块拼图 —— 监督微调(SFT)。它的核心目标,其实就是让模型“听话”:不仅能说得通顺,还要能说得符合人类的预期。
接下来,我们还希望模型变得更聪明——通过人类反馈优化(比如 RLHF),进一步学会给出更加符合人类偏好的回应。
- V me 50!
- Alipay is also ok~


