大语言模型训练原理与实践(四):Reward Model
在上一篇文章中,博主已经简单介绍了 PPO(Proximal Policy Optimization)算法的核心原理。然而,要让算法发挥效果,我们还需要一个关键模块:Reward Model(奖励模型)。这个模型负责为不同的输出生成打分,也就是我们在 PPO 优化目标中多次出现的那个 。换句话说,Reward Model 就是大语言模型训练过程中的“裁判”——它不直接参与回答问题,但会评判哪个回答更符合人类的偏好,从而引导策略模型不断优化生成质量。
模型结构
Reward Model 有两种主流的形式:
- ORM(Outcome Reward Model):对序列整体生成一个得分。
- PRM(Process Reward Model):在序列的生成过程中,分多个步骤,对每一步分别进行打分。
考虑到训练的模型比较简单,我们采用ORM的形式。
Reward Model作为一个为语言模型的生成结果打分的模型,自然需要一定的语言能力,因此通常会选择与策略网络相同架构的语言模型,作为Reward Model的backbone。但与策略网络不同的一点是,Reward Model不输出token序列的概率分布,而是对整个输入序列计算一个标量,作为序列得分,用于评估序列的质量。
具体而言,我们的做法是在backbone的最后接上一个回归头(Regression Head),通常它只是一个简单的线性层,以backbone输出的最后一个token的最后一层隐藏状态作为输入,并输出一个标量值作为Reward。
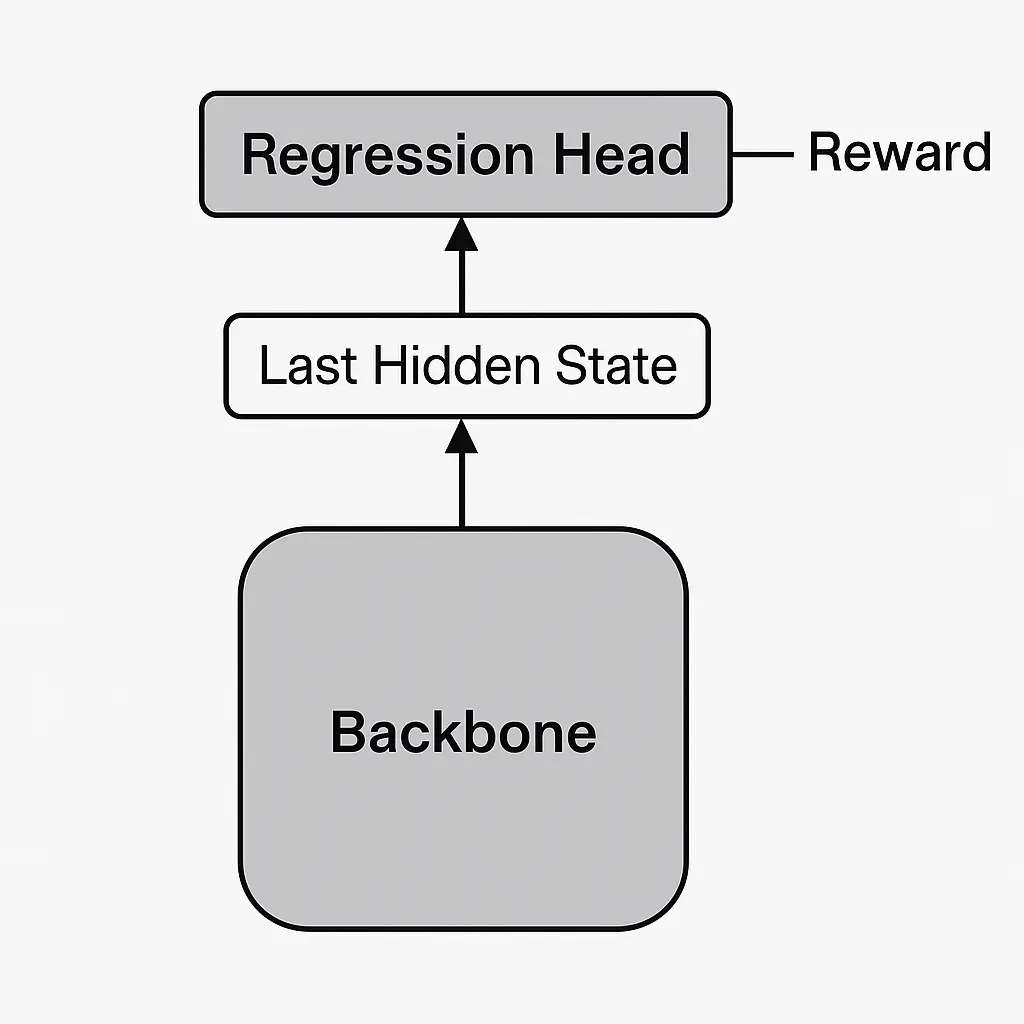
另外还有一种被称为Token-Level Reward Model的评估方案,一看就知道,是对句子中的每一个token计算得到上面的标量值。我在训练时采用的就是这种方案。
数据 & 训练方法
数据准备方面,常见的数据格式是针对每一条prompt,准备两个候选回答,并标注哪个回答更符合人类偏好。一种典型的输入格式如下表所示:
| prompt | chosen | rejected |
|---|---|---|
| 挖掘机技术哪家强? | 中国山东找蓝翔! | 我觉得我最强,因为我玩过模拟城市,里面开过挖掘机。 |
| 请以蔡徐坤的风格做一段自我介绍。 | 全民制作人们大家好,我是练习时长两年半的个人练习生蔡徐坤,喜欢唱、跳、rap、篮球,music! | 大家好,我是蔡徐坤,一名知名的中国艺人。我热爱我的事业,也希望在未来为观众带来更多优秀的作品。谢谢大家的支持。 |
在训练时,我们仍然将数据拼接为与前面训练SFT时的相同格式,即:prompt_ids + bos_token_id + response_ids + eos_token_id,不过这里存在两条不同的response,因此每条数据最终会生成两条序列数据。
我们将两条序列数据分别经过Reward Model的backbone,再将其最后一层隐藏状态作为回归头的输入,最终得到两个得分序列,记为 v_chosen和v_rejected。
然后我们逐token计算两个序列的得分之差:v_chosen - v_rejected。
最终,我们按下面方式进行计算得到两个序列的Pair-Wise Loss:
loss = -F.logsigmoid(v_chosen - v_rejected)为了保证训练稳定性与泛化能力,我们在训练 Reward Model 时通常不对整个模型进行微调,而是采取参数冻结+局部调整的方式,具体而言,我们会将backbone模型的参数冻结,而仅对回归头进行训练。在数据集规模较大的时候,也会在backbone中插入少量LoRA层进行微调,在保证训练稳定性的同时适当增强模型的理解能力。
在我的训练实践中,采用了第一种手段,即只训练回归头。
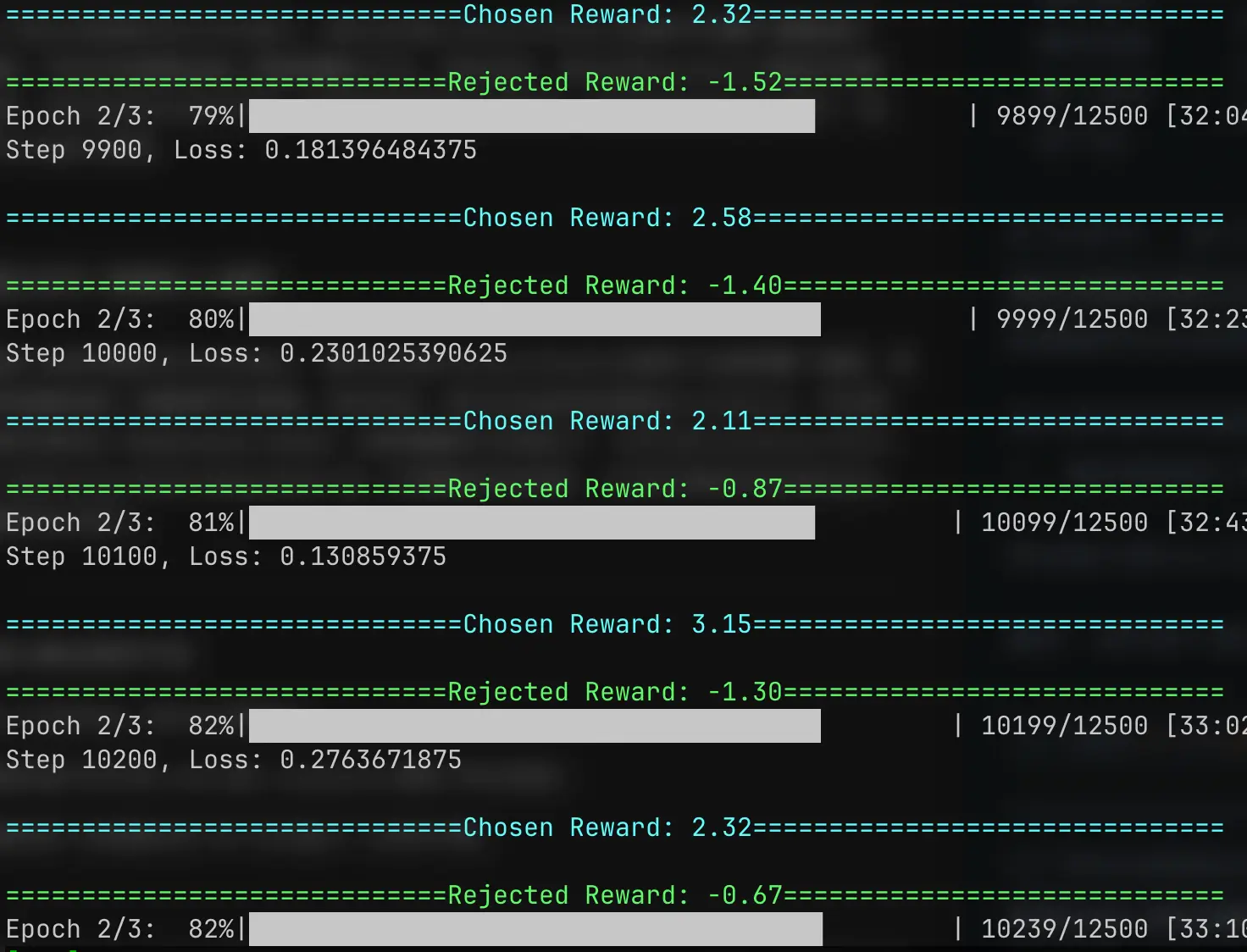
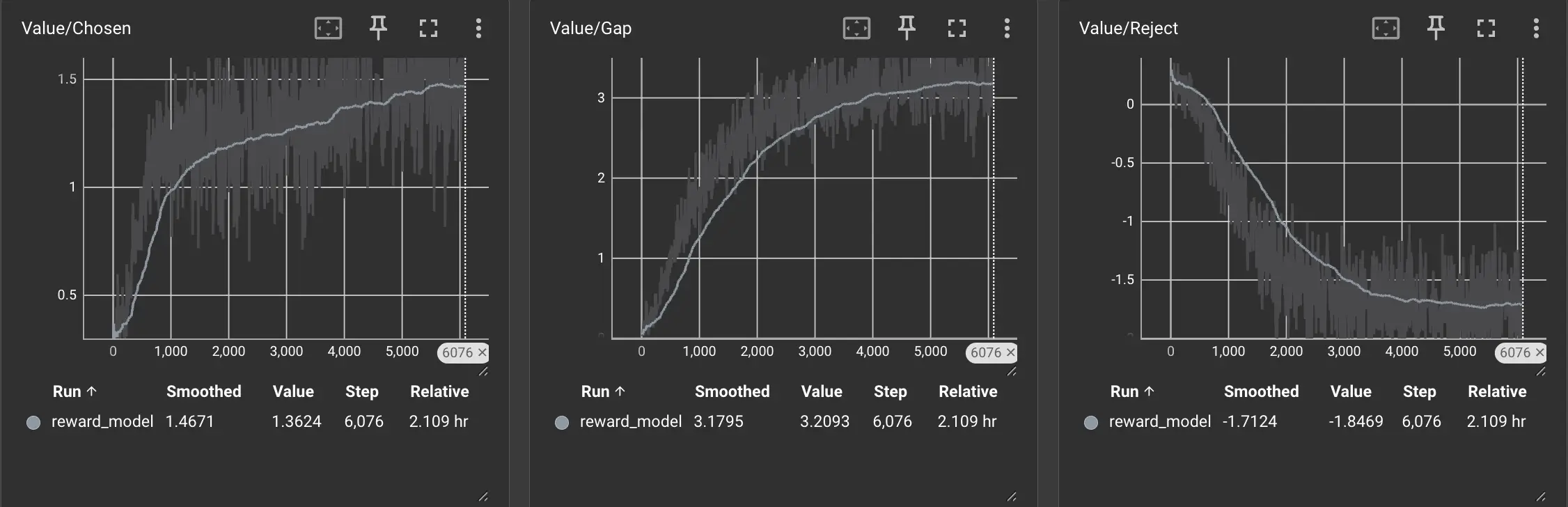
可以看到随着训练的进行,两种回复得到的Reward差距也有了明显提升。
本文涉及到的训练代码详见下面仓库:

- 数据集文件:RM/dataset.py
- 模型文件:RM/model.py
- 训练文件:rm_training.py
到了这里,我们就已经把 RLHF 中的关键角色、主要算法介绍完了。下一篇文章,我们将进入大模型训练的最后一块拼图:RLHF,看看它是怎么把这些角色串联起来、协同合作,让大模型更贴近人类偏好。
- V me 50!
- Alipay is also ok~


