大语言模型训练原理与实践(七):GRPO算法
前情提要
2025年1月27日,因中国 AI 初创企业 DeepSeek 发布低成本高性能模型,英伟达市值单日缩水约6000亿美元,股价暴跌约17%。
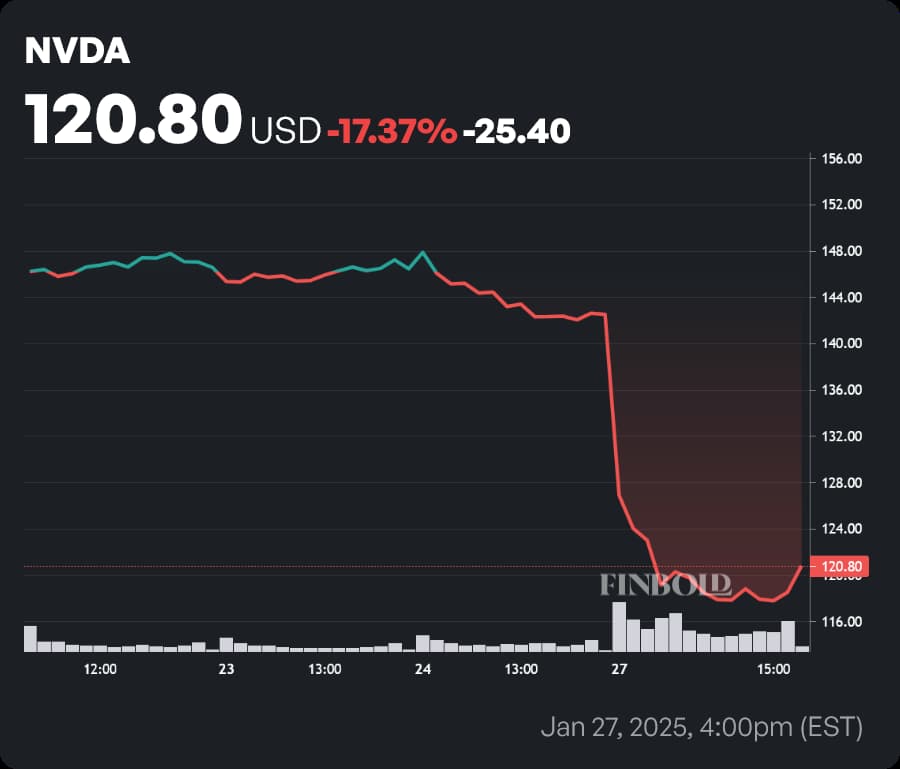
这事在圈内激起了不小的波澜,众所周知,大模型的训练过程十分消耗算力,尤其是常规的RLHF阶段使用的PPO算法,流程复杂又烧钱。比如OpenAI在训练ChatGPT时,动辄上万张A100、H100堆起来跑,而Nvidia几乎是算力的唯一供应商。
而DeepSeek团队推翻了这一现状:训练一个性能能够对标主流水平的大模型,并不需要那么多的卡(仅使用约2k张H800)。他们通过一套更高效、轻量的流程大幅简化了训练的成本与复杂度,其中最核心的改进便是引入了Group Relative Policy Optimization(GRPO)算法。那么,这个算法究竟是何方神圣?感兴趣的朋友可以直接阅读下面的原论文:

插句题外话,博主在当时几乎第一时间就把论文下载了下来:

然而由于实验室搬砖科研等各种事,一直拖着没认真读(唉,读了又怎么样呢?当时的显存连个7b的模型都放不下)。时隔多月,终于显存和心理都空出一点空间,总算能静下心来,把这个 GRPO算法好好研究、复现了一遍。
DeepSeek-R1的论文其实对整体的训练流程也做了不少改进,但核心贡献还是在于其在强化学习阶段引入的GRPO算法,因此我主要研究了这个强化学习算法的细节。
博主写这篇文章的目的,就是记录一下自己对 GRPO 算法的理解,以及在复现过程中整理的一些关键细节和实践心得。
GRPO算法的思想
GRPO算法,即组相对策略优化(Group Relative Policy Optimization),其核心思想是:不再单独对一个token序列打分,而是在同一个prompt下采样多条输出,形成一个分组,然后在分组中计算输出间的相对优劣,得到每条输出的组内相对得分,以此指导模型更新。
除此以外,GRPO算法和先前的PPO算法还有一些区别:
- GRPO算法省去了Reward Model与Critic Model。
- 论文针对任务数据集特点设计了一些基于规则的Reward Function,来对输出进行打分。
- 与PPO算法中token-level的优势函数不同,GRPO算法中的优势函数是sample-level的,即一个输出的所有token共享同一个组内优势值。
- GRPO算法将PPO算法的Reward中添加的KL正则项移到了损失函数中。
- GRPO算法使用了另一种不同的KL散度估计方法。
我们来逐点分析。首先看第二点,论文中提到:
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
我在微调RLHF的时候确实也遇到过这种情况。常规PPO算法非常依赖于Reward Model的质量,但基于神经网络的Reward Model在用于强化学习时经常会遇到Reward Hacking,即模型在训练时学会了钻Reward Model的漏子,用一些不好的输出获取非常高的得分,即模型学会了“讨好”奖励模型,而不去努力产生高质量的输出(不好,这怎么像极了我做科研时的样子)。
而对神经网络攻击稍有了解的朋友就会知道,神经网络模型作为一个高度不可解释的黑盒系统,很容易被“投其所好”地构造出满足特定输出的输入 —— 即使这些输入在人类看来是无意义甚至错误的。
正是由于这种脆弱性,我们训练的语言模型只需要偶然间发现一条让奖励模型输出高分的捷径,它就可能在这条离谱的道路上越走越远,或产生模式崩坏、或输出质量奇差的内容。
不好,跑题了。。。
那么论文提到的基于规则的Reward函数主要有两种:
- 基于正确性的奖励(Accuracy rewards):对于一些有“标准答案”的任务,例如具有准确答案的数学问题、代码生成任务等,可以根据模型答题是否准确来给一定的奖励。
- 基于格式的奖励(Format rewards):根据模型的输出结果是否满足一定的格式要求来进行给分。如论文提到将模型的思维过程置于
<think>和</think>标签之间,如模型输出的内容满足此条件则给奖励。
不过,对于通用型任务而言,Accuracy rewards不一定能定义,这种情况下,也许还得和前面PPO算法类似,去训练一个通用的Reward Model来辅助。
对于第一点,既然都定义了基于规则的奖励函数了,那么Reward Model、Critic Model自然是不需要了。
我们来看第三点。
在PPO算法中,优势函数的计算分为以下步骤:
- 通过Critic Model计算每个token的Value。
- 通过每个token的Value计算TD delta(时序差分序列)。
- 通过时序差分序列按GAE算法计算优势函数。
对这一过程的细节不太了解的朋友可以翻看我前面的文章:PPO算法、RLHF实践。
由此可见,PPO算法中的优势函数也是token-level的,即每个token对应一个优势值。
但在GRPO算法中,则有所不同,如论文中所写,GRPO算法使用的优势函数是通过组内每个样本的Reward计算得来的:
诶,我们发现,这样一来,相当于每个样本中的所有token是共享同一个优势函数值的。
再看第四点和第五点,我们回顾PPO算法的优化目标:
在Reward中添加了一个KL散度惩罚项,而GRPO算法中则将这一项惩罚项移到了损失函数中:
容易发现,除掉多了个分组大小 以外,GRPO的损失函数前半部分与PPO是完全一致的,而后面多出来的部分就是KL散度惩罚项。
PPO中,计算KL散度的公式是:
而在GRPO中,论文采用了下面这个公式:
显然,前者是后者的一个一阶近似,故后者能够更准确地估计真实的KL散度。
GRPO算法复现
- Pretrained-Model:Qwen/Qwen2.5-1.5B-Instruct (太惨了,即使套了LoRA也只训的动1.5B)
- Dataset:openai/gsm8k 包含数千道英文小学数学题的数据集,每条数据包含一个
answer字段,提供问题的解答,并且固定了纯数字答案格式:置于末尾####之后。 - Task:让模型具备使用思维链解决数学问题的能力。
奖励函数定义
与论文一致,我们主要定义了两个奖励函数:
- 准确性奖励:我们要求模型给出问题的答案,如答案准确则奖励。
- 格式奖励:要求模型将思考过程包含在一对
<think>和</think>之间,并且将最终答案包含在一对<answer>和</answer>之间,如格式准确则奖励。
另外,考虑到严格达成两个奖励函数非常困难,我们还相应地提供了两个稍宽松的奖励。
- 只要答案是一个纯数字,就给一定的奖励。
- 只要匹配到了
<think>、</think>、<answer>和</answer>中的一部分,就给一定的奖励,但如果匹配到多个,则扣除奖励。
奖励函数的定义详见此文件。
数据处理
我们直接套用Qwen/Qwen2.5-1.5B-Instruct模型对应的tokenizer所提供的chat template,并定义一个系统提示词:
You are given a problem.
Think about it and provide your working out.
Place it between <think> and </think>.
Then, provide your numeric answer between <answer> and </answer>. For example:
<think>
...
</think>
<answer>
...
</answer>核心代码:
def extract_hash_answer(self, text: str):
if "####" not in text:
return None
return text.split("####")[1].strip().replace(',', '')
def __getitem__(self, idx):
data = self.dataset[idx]
question = data['question']
answer = self.extract_hash_answer(data['answer'])
prompt = self.tokenizer.apply_chat_template([
{"role": "system", 'content': self.system_prompt},
{"role": "user", 'content': question}
], add_generation_prompt=True, tokenize=False)
return {
'prompt': prompt,
'answer': str(answer)
}训练流程
甚至连伪代码都懒得写了,大概写一下流程吧:
- 定义一个数据收集容器:Data Buffer。
- 从数据集中取一条 prompt,生成 条输出序列,从而得到大小为 的分组。
- 根据定义好的奖励函数,对步骤 2 生成分组内的所有输出序列计算得分,然后在组内进行比较,求得相对得分(作为优势函数)。由此,得到一组数据。
- 将步骤 3 得到的数据添加到Data Buffer。
- 若Data Buffer的大小达到一次迭代需要的数据量(等效 Batch size),则进入步骤 6,否则回到步骤 2。
- 遍历Data Buffer,每次取Batch size个数据,按前面的公式计算KL散度、损失函数,并进行策略迭代。
- 遍历完成,清空Data Buffer,回到步骤 2。
本部分完整代码见文末仓库。
训练效果
训练曲线:
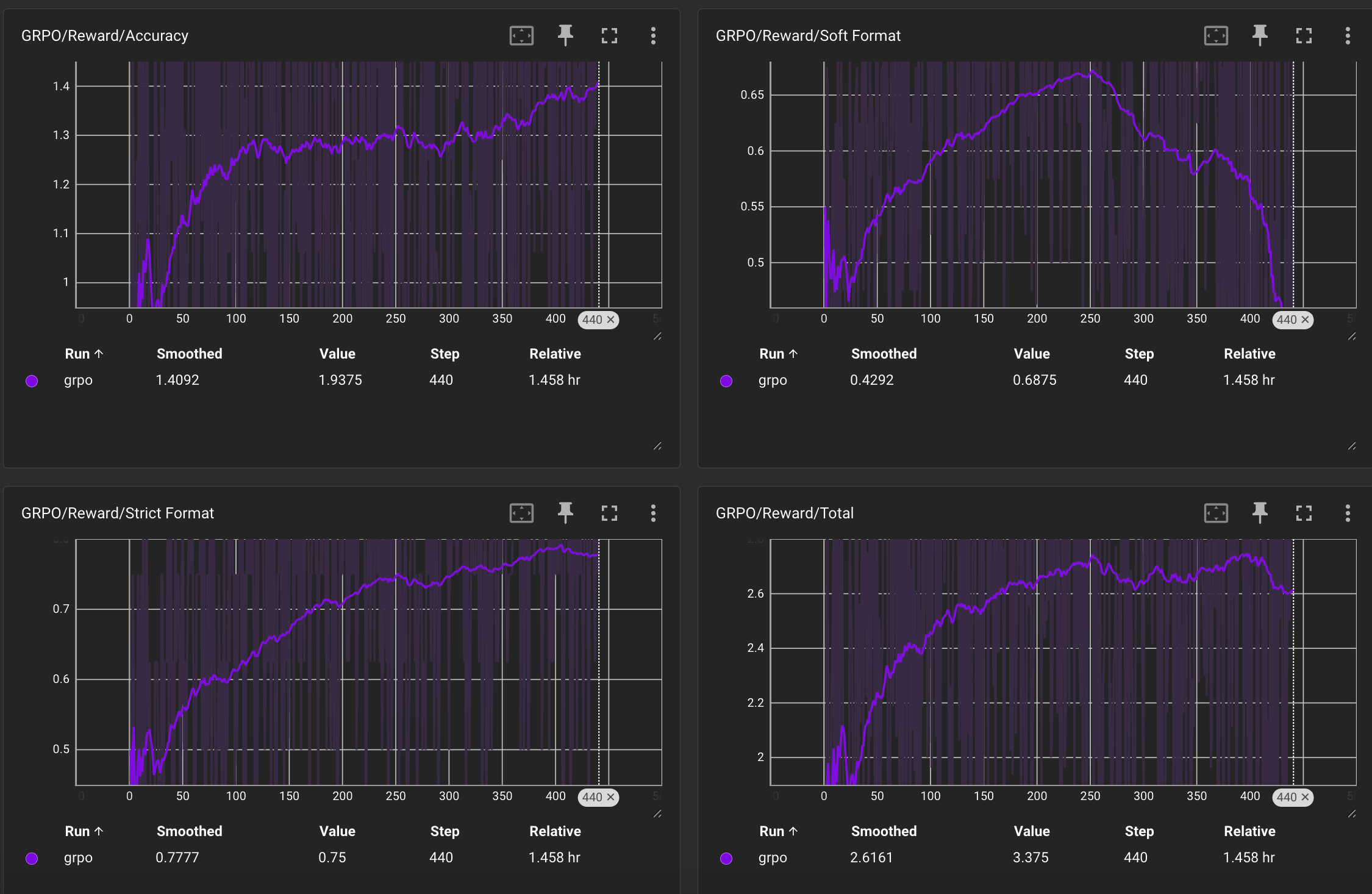
注意到总体 Reward 还是在上升的,并且我们还分别记录观察了三个独立的Reward函数的变化趋势,发现模型在准确率、格式方面都有所提升,唯独这个Soft Format在上升到一定程度后有所下降,观察到模型有时会重复输出answer的闭合tag:</answer>,目前还不知道是什么原因(明明给了一定的惩罚?)。
另外,每隔10次迭代,打印了一下模型生成的结果,发现模型确实能做对一些题,并且在格式上也有所对齐,思考过程有模有样。下面贴出几个例子。
最终,博主将迭代了400个step的模型与未经过训练的初始模型进行了测试与对比,结果如下:
Qwen Accuracy: 0.4314 Formatted: 0.6088 GRPO Accuracy: 0.5610 Formatted: 0.9121可见经过GRPO迭代的模型已经具备了较强的格式对齐能力,在准确率方面也有了一定的提升,意味着训练还是有一定的效果的。
本文相关代码已开源于下面仓库:
由于实验中途突然被抓去跑了一些别的东西,只好先把实验停了,在无法确保实验最终效果的情况下,尚未开源本文代码,敬请期待!
只是实现了一个微小的demo,在细节方面仍有所欠缺,有待进一步斟酌,希望大佬们不吝赐教!
- V me 50!
- Alipay is also ok~


