在消费级显卡上部署QwQ-32B模型
AI摘要Kimi Chat
Qwen在今年3月份的时候发布了号称能媲美DeepSeek-R1-671B的32B模型:QwQ(这名字卖萌是故意的,还是不小心?)
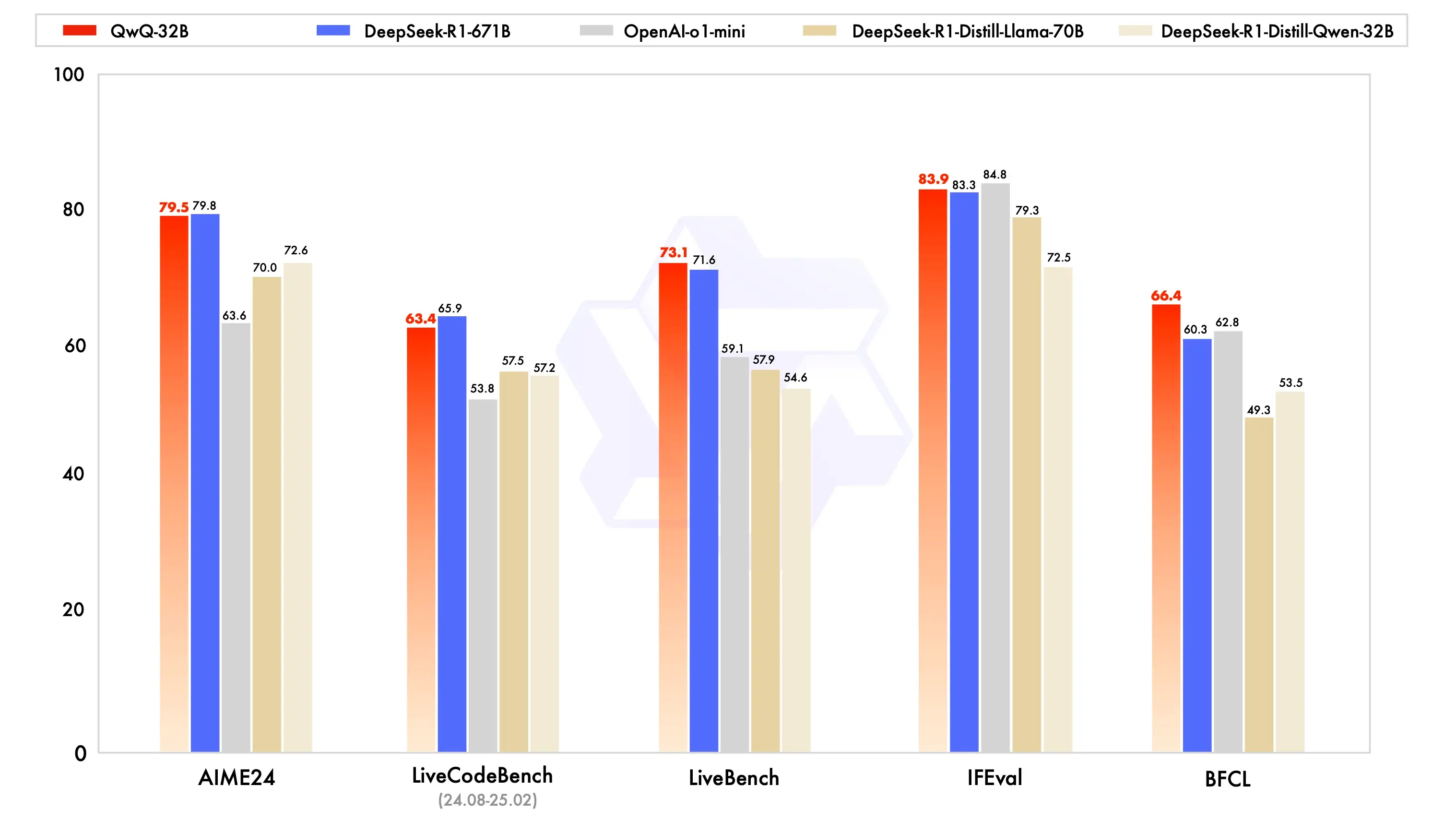
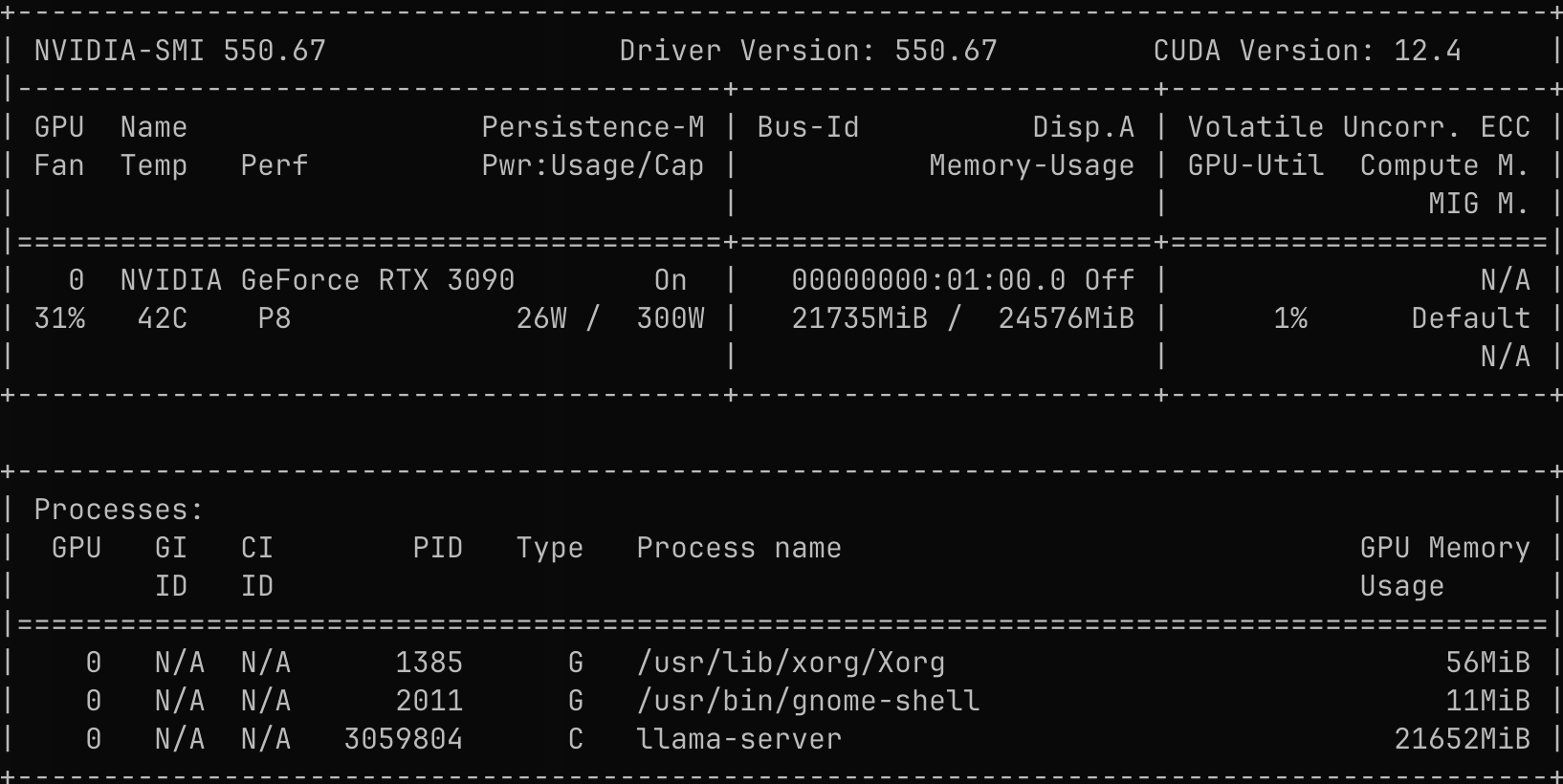
32B模型如果做一个4bit量化的话,大约只需要占16G的显存,这样的话,一块24G显存的消费级显卡(如NVIDIA GeForce RTX 3090)也能把这个模型部署起来。拥有一个本地部署的性能匹配满血DeepSeek-R1的模型岂不美哉?于是,我紧锣密鼓地一顿部署,很快便搞定了。
下载模型
模型的官方链接位于Qwen/QwQ-32B,不过我这里选择了另一个HuggingFace 上的由bartowski提供的 该模型的 llama.cpp/ggml 格式量化版仓库:bartowski/Qwen_QwQ-32B-GGUF。
找到文件:Qwen_QwQ-32B-IQ4_XS.gguf,用wget下到本地即可。
安装 llama.cpp
这是一个用cpp写的大模型推理框架,链接如下:
引用站外地址,不保证站点的可用性和安全性

llama.cpp
GitHub
仓库给了一个编译文档,不过我直接对着文档操作失败了,所以在这里记录一下我的操作。
在编译之前,需要确保已经安装好了一些基本的组件:
sudo apt update
sudo apt install -y build-essential libcurl4-openssl-dev
sudo snap install cmake --classic另外如果编译CUDA版,还需要装好cuda-toolkit:
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Feb_27_16:19:38_PST_2024
Cuda compilation tools, release 12.4, V12.4.99
Build cuda_12.4.r12.4/compiler.33961263_0增加CUDA路径
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHClone仓库
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp开始编译
env -i \
PATH="/snap/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/bin:/usr/local/cuda/bin" \
CC=/usr/bin/gcc CXX=/usr/bin/g++ \
CUDACXX=/usr/local/cuda/bin/nvcc \
cmake -B build -DGGML_CUDA=ON \
-DCMAKE_C_FLAGS="-pthread" \
-DCMAKE_CXX_FLAGS="-pthread" \
-DCMAKE_EXE_LINKER_FLAGS="-pthread" \
-DCUDAToolkit_ROOT=/usr/local/cuda
cmake --build build -j4 # 4核足以,开太多会把我ssh挤掉编译完成后,将编译出的文件移动到系统上:
sudo cmake --install build --prefix /usr/local这时直接运行llama-server仍可能会报错:
llama-server: error while loading shared libraries: libmtmd.so: cannot open shared object file: No such file or directory运行一下下面的命令即可:
# 确保 /usr/local/lib 在动态库配置里,并刷新缓存
echo '/usr/local/lib' | sudo tee /etc/ld.so.conf.d/llama.conf
sudo ldconfig部署 QwQ-32B
创建一个jinja模板./chat_templates/QwQ.jinja:
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- '' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" and not message.tool_calls %}
{%- set content = (((message.content | default('', true))).split('</think>')|last).lstrip('\n') %}
{{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{%- set content = (((message.content | default('', true))).split('</think>')|last).lstrip('\n') %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n<think>\n' }}
{%- endif %}创建启动命令文件llama_deploy.sh:
llama-server \
--model "./model/bartowski/Qwen_QwQ-32B-GGUF/Qwen_QwQ-32B-IQ4_XS.gguf" \
--alias "QwQ-32B" \
--n-gpu-layers 65 \
--ctx-size 32768 \
--parallel 1 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--threads 16 \
--flash-attn \
--mlock \
--n-predict -1 \
--jinja \
--chat-template-file ./chat_templates/QwQ.jinja \
--host 0.0.0.0 \
--port 8000
然后运行llama_deploy.sh,即可完成部署。
测试

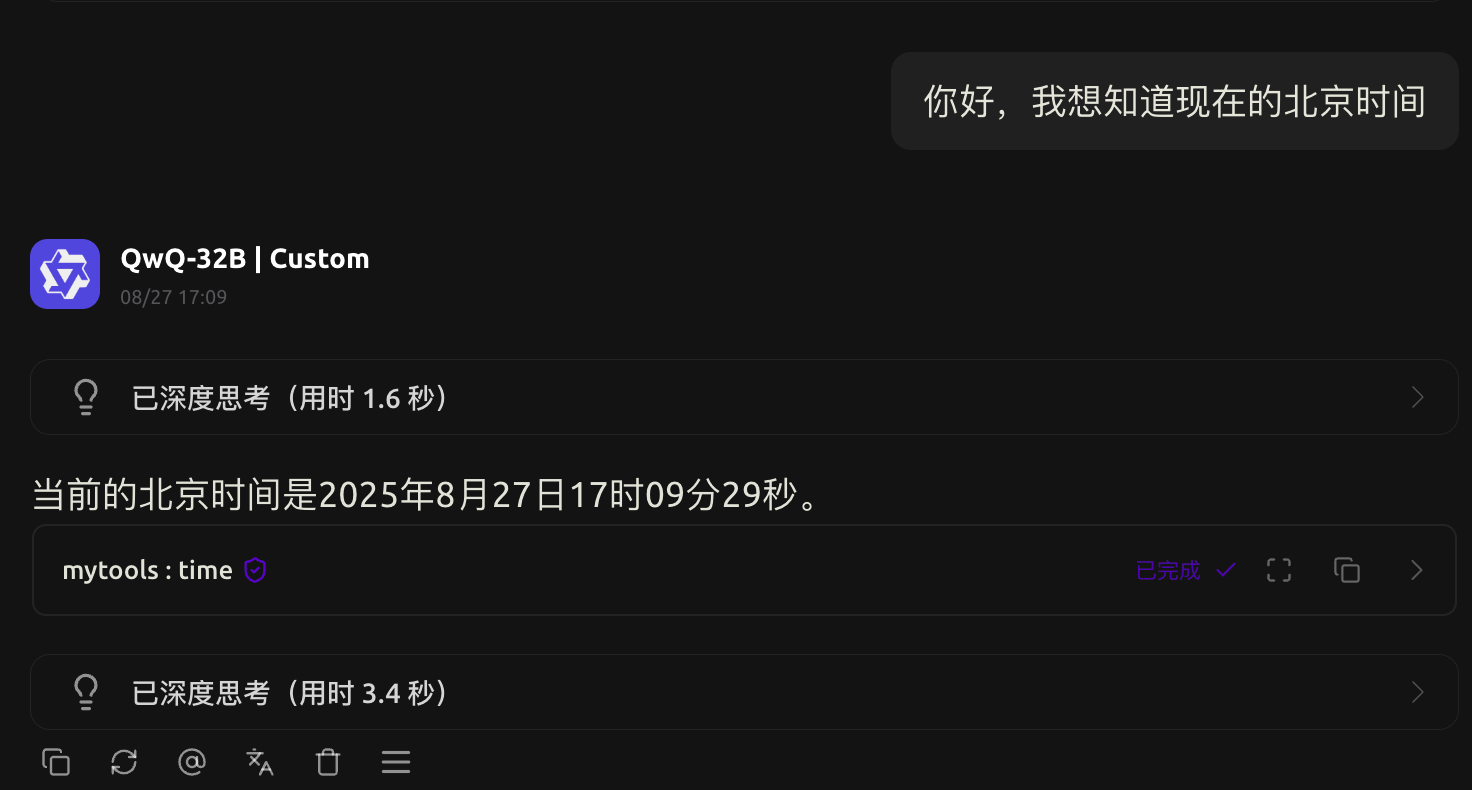
在Cherry Studio中还能轻松调用工具:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 逸风亭!
- V me 50!
- Alipay is also ok~


相关推荐



评论
TwikooGiscus