从零开始的麻将AI论文复现(零)
前段时间,博主突然开始沉迷偶尔玩玩立直麻将,受自己“职业病”的影响,遂想着能不能搞个AI出来帮我上段。
先找找有没有现成的算法。上网一搜,发现果然早有不少麻将AI的算法诞生了,比如东京大学开发的「爆打」、由Dwango发布的「NAGA25」、由MSRA开发的「Suphx」等。看了一圈,决定试着复现一下「Suphx」。
论文简介
论文传送门如下:

如论文所说,该算法仅在监督学习下就能达到人类顶级水平,而在self-play以及reinforcement learning算法的加持下,Suphx能够达到特上房的最高段位十段,其稳定段位更是能达到8.7段,远超人类高手的稳定段位:7.4段。
Suphx并没有开源代码,因此唯一能参考的只有MSRA的研发团队放到arXiv上的这篇论文(当然还有众多鱼龙混杂的解读文),然而该论文写的比较简略,有许多细节并未阐述,大概是MSRA的大佬们认为这些都是简单易得的。在这些尚未拨开云雾的细节问题上,就需要发挥自己的想象力了。
这篇论文复现起来应该是一个大工程,因此本系列将会持续更新,直到我复现失败或者不想玩了为止。
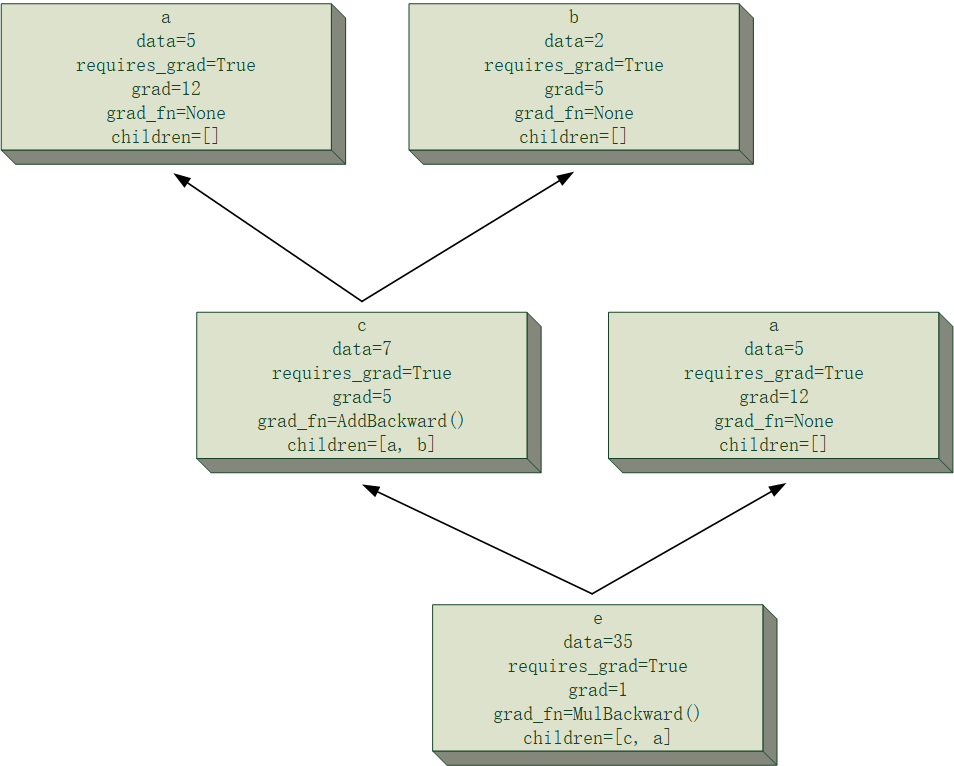
通过阅读论文,容易发现Suphx首先是通过监督学习进行训练的,为的是使得模型快速习得麻将的复杂规则。Suphx是由多个模型组合而成的一个决策模型,这些子模型分别是「弃牌模型」、「立直模型」、「吃模型」、「碰模型」、「杠模型」以及「和牌模型」。其中「和牌模型」比较简单,使用了基于规则的算法(我在复现时更是直接采用了能和就和的zz策略),而其他模型则都使用了残差卷积神经网络结构。例如:「弃牌模型」输入当前局面的编码,输出一个34维向量(立直麻将共有34种牌),这个向量即表示模型的切牌倾向,选择argmax对应的牌切出即可。而「吃、碰、杠、立直模型」则都是二分类模型,输出2维向量(或一个标量)表示模型在决策上的倾向。
我的成果
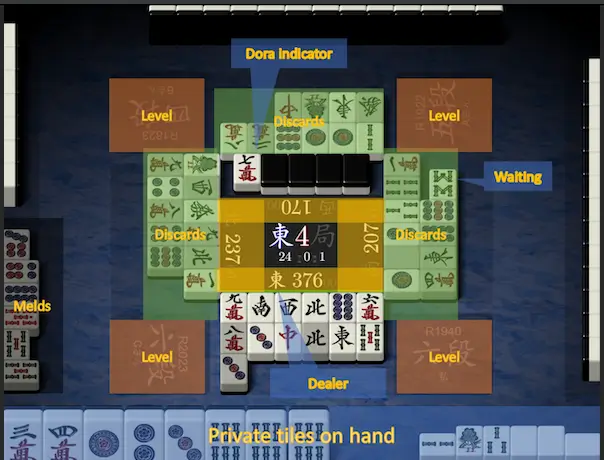
在开始写这篇文章时,我已基本复现完成监督学习的部分,并且AI确实已经有点能打了(我本人和三个经监督学习的AI打了多个半庄,感觉吃1比较困难,当然这个不排除我自己比较菜的可能)。下面贴出一些AI的“战绩”以及我疏于防守然后被AI击飞的冥场面。可见仅仅经过非常有限的监督学习后的AI,已经相当有做牌思路了。
一些截图
若您想对此辣鸡模型的效果有更加直观的认识,可以通过访问这个链接观看模型的self-play(暂时关闭)。
作为本系列的第一篇文章,本文就先简简单单写一下监督学习的数据集的来源与处理。
数据来源与处理
Suphx的监督学习数据来源于最高水平立直麻将平台「天鳳」,为了提升数据质量,减少数据噪声,采用了天鳳平台凤凰桌的对局数据。一个典型的天鳳牌谱格式为XML,牌谱中具体的标签含义可以查看这篇文章,其已写的非常详细。我们可以通过遍历牌谱文件来回放对局,因此首先需要编写一个麻将游戏的class,简单实现一下所有需要的游戏接口。由于游戏实现并非本文的重点,这里省略,可以直接参考我的项目代码,后文可能会对一些细节进行说明。
由牌谱生成数据的方法非常简单,牌谱XML文件中的每一个节点均表示一个游戏中的事件,如“某玩家摸进一张一饼”、“某玩家开了个白板的暗杠”、“翻了一张新dora指示牌:三万”等等,我们只要遍历XML文件的所有节点,节点在干啥,我们就干啥,这样即可对一个牌谱进行playback。以训练「弃牌模型」所需要的数据为例,我们首先确定一个观察目标(比如整个半庄结束后的胜利玩家),在遍历到该玩家的弃牌行为节点时,将当前局面编码为特征,同时将该玩家所弃的牌作为标签,我们由此就可以得到一系列的(特征,标签)对。
牌谱中比较难处理的是标签为“N”的节点,该标签表示一次鸣牌,然而鸣牌被记录为了人看不懂的形式,例如<N who="1" m="3495"/>,这其实是天鳳平台对鸣牌进行了编码,可以参考天鳳の牌譜形式态解析这篇文章或直接阅读天鳳的代码。
下一篇文章将说明我自己对游戏局面进行编码的方法。
- V me 50!
- Alipay is also ok~