部署Qwen3-32B模型并使用Cherry Studio优雅接入的一些尝试
前两天尝试在一块3090上部署了一个QwQ-32B(见下面这篇文章)。
不过这个模型是一个推理模型(Reasoning model),它面对任何问题都会“陷入沉思”,思考过后之后才给出回答,对于某些需要快速响应但比较简单的任务而言就有点令人不耐烦了,因此,后来我又重新尝试了其他的模型,例如Qwen3-32B,这个模型则是个混合推理模型(Hybrid reasoning model),也就是说这个模型存在两种模式:思考模型与非思考模式,可针对复杂问题启用多步逻辑推理,简单任务则快速响应。
模型部署
这部分总体与上面那篇文章中部署QwQ的过程类似,使用llama_server进行部署,不过为了与Cherry Studio良好适配,我还进行了一些调整。
首先是到处乱抄糊了一个jinja模板,命名为了my-template.jinja
{%- if messages[0].role == 'system' %}
{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}
{%- endif %}
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
{%- for forward_message in messages %}
{%- set index = (messages|length - 1) - loop.index0 %}
{%- set message = messages[index] %}
{%- set current_content = message.content if message.content is not none else '' %}
{%- set tool_start = '<tool_response>' %}
{%- set tool_start_length = tool_start|length %}
{%- set start_of_message = current_content[:tool_start_length] %}
{%- set tool_end = '</tool_response>' %}
{%- set tool_end_length = tool_end|length %}
{%- set start_pos = (current_content|length) - tool_end_length %}
{%- if start_pos < 0 %}
{%- set start_pos = 0 %}
{%- endif %}
{%- set end_of_message = current_content[start_pos:] %}
{%- if ns.multi_step_tool and message.role == "user" and not(start_of_message == tool_start and end_of_message == tool_end) %}
{%- set ns.multi_step_tool = false %}
{%- set ns.last_query_index = index %}
{%- endif %}
{%- endfor %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{%- set content = message.content %}
{%- set reasoning_content = '' %}
{%- if message.reasoning_content is defined and message.reasoning_content is not none %}
{%- set reasoning_content = message.reasoning_content %}
{%- else %}
{%- if '</think>' in message.content %}
{%- set content = (message.content.split('</think>')|last).lstrip('\n') %}
{%- set reasoning_content = (message.content.split('</think>')|first).rstrip('\n') %}
{%- set reasoning_content = (reasoning_content.split('<think>')|last).lstrip('\n') %}
{%- endif %}
{%- endif %}
{%- if loop.index0 > ns.last_query_index %}
{%- if loop.last or (not loop.last and reasoning_content) %}
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content.strip('\n') + '\n</think>\n\n' + content.lstrip('\n') }}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- if message.tool_calls %}
{%- for tool_call in message.tool_calls %}
{%- if (loop.first and content) or (not loop.first) %}
{{- '\n' }}
{%- endif %}
{%- if tool_call.function %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{%- if tool_call.arguments is string %}
{{- tool_call.arguments }}
{%- else %}
{{- tool_call.arguments | tojson }}
{%- endif %}
{{- '}\n</tool_call>' }}
{%- endfor %}
{%- endif %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
{%- endif %}可以注意到主要是在提示词中拼接了工具的调用过程(即和function call相关)。另外还有最后增加了一个thinking mode的开关:enable_thinking,通过指定此参数为False,可以直接让<think>标签对闭合,以使得模型跳过思考。
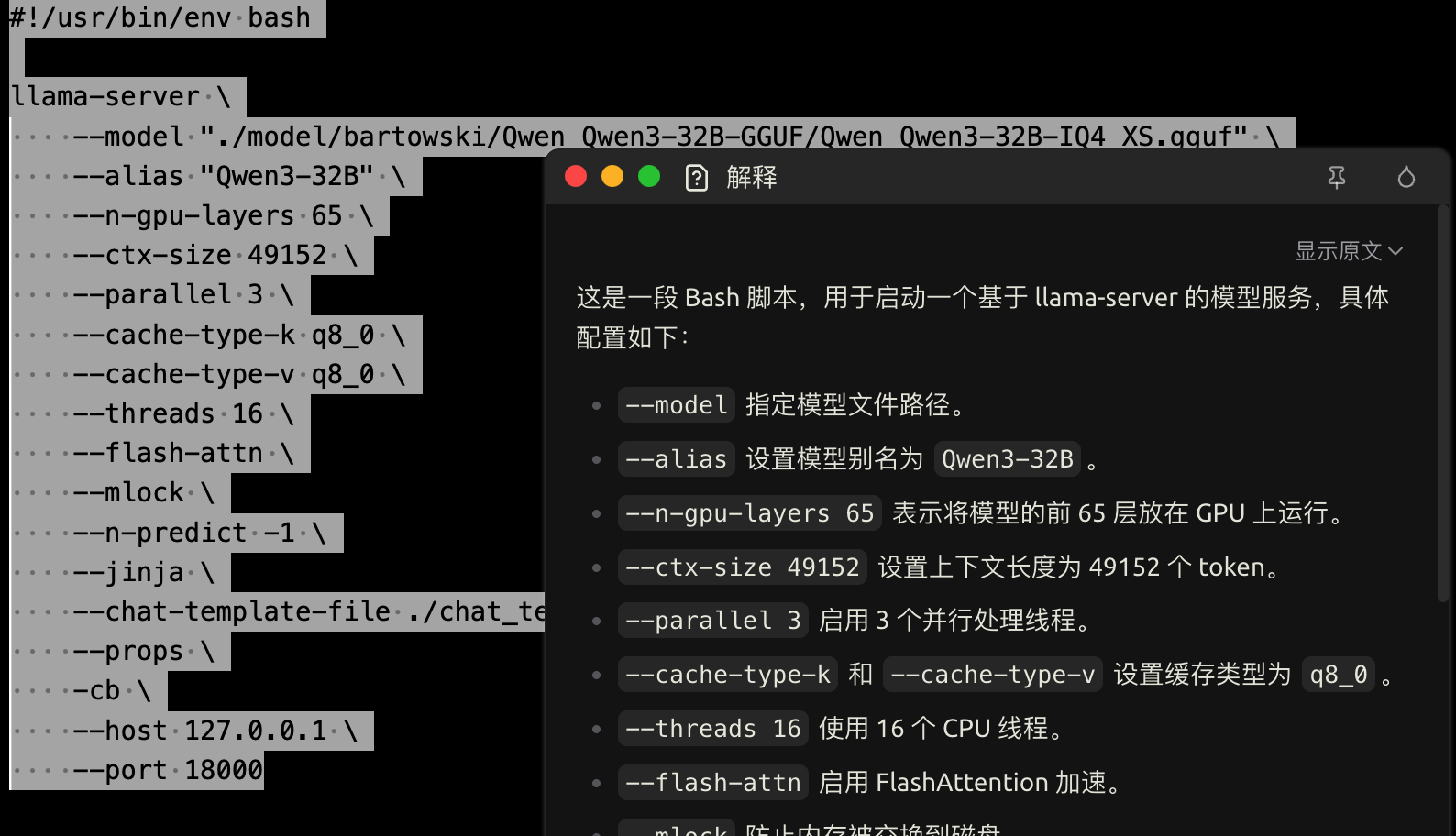
接下来是启动文件:
#!/usr/bin/env bash
llama-server \
--model "./model/bartowski/Qwen_Qwen3-32B-GGUF/Qwen_Qwen3-32B-IQ4_XS.gguf" \
--alias "Qwen3-32B" \
--n-gpu-layers 65 \
--ctx-size 49152 \
--context-shift \
--parallel 3 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--threads 16 \
--flash-attn \
--mlock \
--n-predict -1 \
--jinja \
--chat-template-file ./chat_templates/my-template.jinja\
--props \
-cb \
--host 127.0.0.1 \
--port 18000
稍做了一些修改,例如把监听的地址改成了本地,后面我还专门写了一个代理脚本作为中间层供非本地交互。
代理脚本如下:llm_proxy.py:
import os
import json
from typing import Optional, Set
from fastapi import FastAPI, Request, Header, HTTPException
from fastapi.responses import JSONResponse, StreamingResponse, Response
import httpx
UPSTREAM_BASE = "http://127.0.0.1:18000"
PROXY_API_KEYS = set()
UPSTREAM_API_KEY = "" # 可选, 若上游需要鉴权则设置
app = FastAPI(title="LLM Proxy")
_api_keys: Set[str] = set()
_api_keys_file = "./.llama_api_keys"
def read_api_keys() -> Set[str]:
keys = set()
with open(_api_keys_file, "r", encoding="utf-8") as f:
for line in f:
k = line.strip()
if k:
keys.add(k)
print(f"[INFO] Loaded API keys: {len(keys)} keys")
return keys
_api_keys = read_api_keys()
def check_auth(auth: str | None):
if not _api_keys:
return # 未设置则不启用代理鉴权
if not auth or not auth.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Missing Authorization Bearer")
if auth.split(" ", 1)[1].strip() not in _api_keys:
raise HTTPException(status_code=403, detail="Invalid API key")
def upstream_headers(orig_auth: str | None):
h = {"Content-Type": "application/json"}
if UPSTREAM_API_KEY:
h["Authorization"] = f"Bearer {UPSTREAM_API_KEY}"
return h
def _should_stream(path: str, payload: dict) -> bool:
"""仅对 chat/completions 和 completions 且 stream=true 的 POST 开启 SSE 透传。"""
p = path.lower()
if ("chat/completions" in p or p.endswith("/completions")) and isinstance(payload, dict):
return bool(payload.get("stream"))
return False
@app.get("/")
def root():
return {"name": "LLM Proxy", "upstream": UPSTREAM_BASE, "v1_proxy": True}
@app.get("/props")
async def proxy_props(request: Request):
async with httpx.AsyncClient() as client:
resp = await client.get(
f"{UPSTREAM_BASE}/props",
params=request.query_params,
headers=request.headers
)
return JSONResponse(status_code=resp.status_code, content=resp.json())
@app.get("/health")
async def proxy_props(request: Request):
async with httpx.AsyncClient() as client:
resp = await client.get(
f"{UPSTREAM_BASE}/health",
params=request.query_params,
headers=request.headers
)
return JSONResponse(status_code=resp.status_code, content=resp.json())
def modify_post_payload(payload):
ctk = payload.get("chat_template_kwargs")
if not isinstance(ctk, dict):
ctk = {}
chat_template_kwargs = ['enable_thinking']
for k in chat_template_kwargs:
if k in payload:
v = payload[k]
if v is not None:
ctk[k] = v
payload["chat_template_kwargs"] = ctk
return payload
@app.api_route("/v1/{full_path:path}", methods=["GET", "POST", "PUT", "PATCH", "DELETE", "OPTIONS"])
async def v1_catch_all(
request: Request,
full_path: str,
authorization: Optional[str] = Header(default=None),
):
"""
原样转发 /v1/** 的所有请求到上游。
- JSON 请求:优先使用 json= 传递(便于上游解析)。
- multipart/二进制:透传 content。
- chat/completions & completions + stream=true:SSE 流式透传。
"""
check_auth(authorization)
upstream_url = f"{UPSTREAM_BASE}/v1/{full_path}"
method = request.method.upper()
params = dict(request.query_params)
raw_body = await request.body()
ct_req = request.headers.get("content-type", "")
headers = upstream_headers(authorization)
fwd_headers = {**headers}
if ct_req:
fwd_headers["Content-Type"] = ct_req
payload: Optional[dict] = None
if "application/json" in ct_req.lower() and raw_body:
try:
payload = json.loads(raw_body.decode("utf-8"))
except Exception:
payload = None
if payload is not None and isinstance(payload, dict):
payload = modify_post_payload(payload)
if method == "POST" and payload is not None and _should_stream(full_path, payload):
async def iter_stream():
async with httpx.AsyncClient(timeout=None) as client:
async with client.stream(
"POST",
upstream_url,
headers=fwd_headers,
json=payload,
params=params,
) as r:
r.raise_for_status()
async for chunk in r.aiter_bytes():
yield chunk
return StreamingResponse(iter_stream(), media_type="text/event-stream")
async with httpx.AsyncClient(timeout=None) as client:
kwargs = dict(url=upstream_url, headers=fwd_headers, params=params)
if method in {"POST", "PUT", "PATCH"}:
if payload is not None:
kwargs["json"] = payload
else:
kwargs["content"] = raw_body
r = await client.request(method, **kwargs)
ct_resp = r.headers.get("content-type")
resp_headers = {}
for k in ("content-type", "content-disposition", "cache-control", "x-request-id"):
if k in r.headers:
resp_headers[k] = r.headers[k]
return Response(
content=r.content,
status_code=r.status_code,
media_type=ct_resp,
headers=resp_headers,
)这部分实现了一个比较简陋的鉴权功能,其他的操作就是把请求内容透传到上游即可。
为了适配Cherry Studio和我的后端服务llama_server,还需要将enable_thinking这个参数的位置移动一下,放置到chat_template_kwargs,不然模板不会渲染。
通过命令启动:
uvicorn llm_proxy:app --host 0.0.0.0 --port 8000至此,服务端的配置已经完成。
配置 Cherry Studio
创建模型
在「模型服务」tab下找到「阿里云百炼」,删掉所有的默认模型,将API修改为刚刚的自部署服务,填写一个密钥。随后添加新模型:
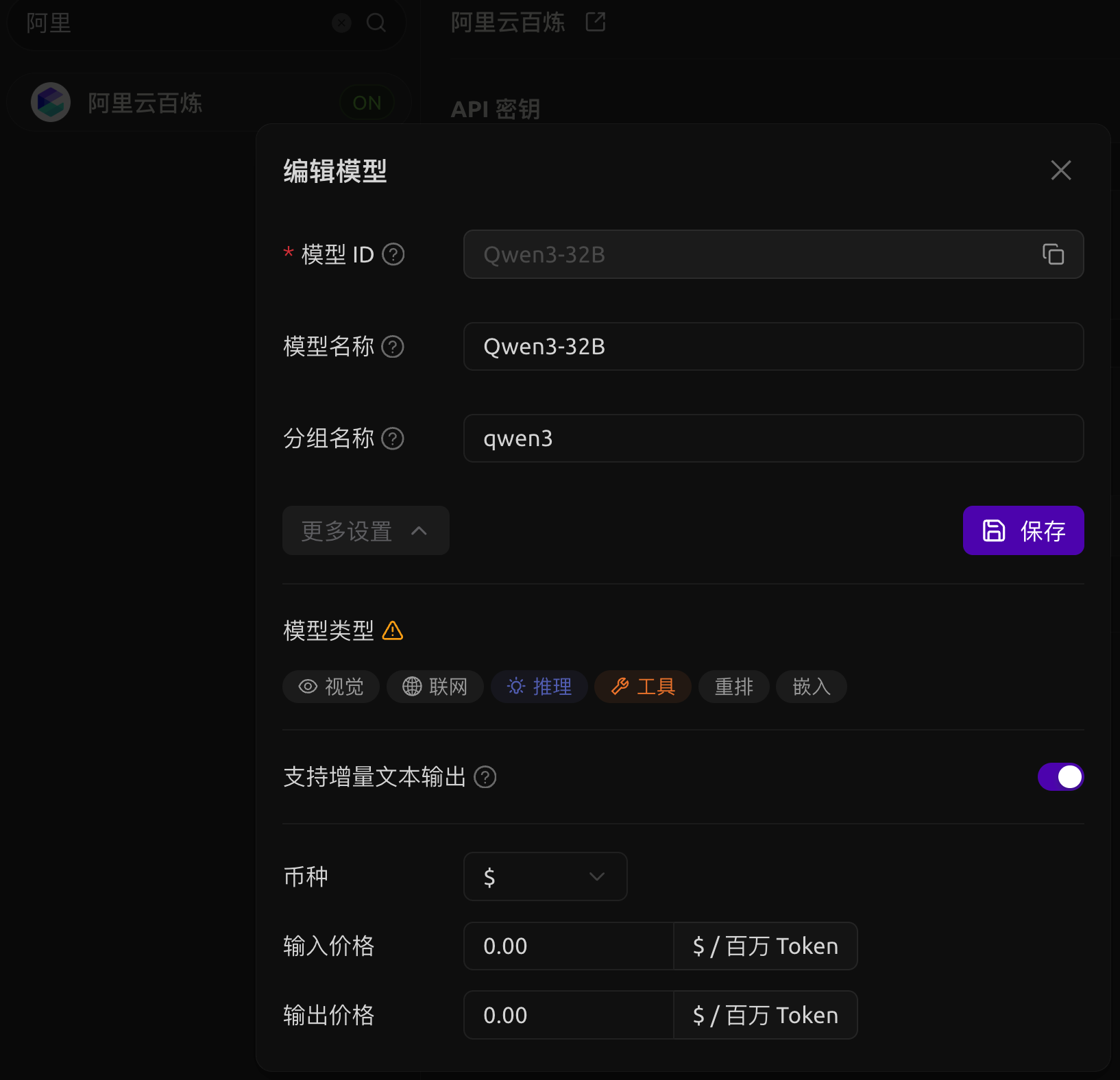
之所以使用「阿里云百炼」是因为这个服务能开启、关闭思维链(也有一些其他服务支持思维链,不过我没有尝试)
配置默认模型
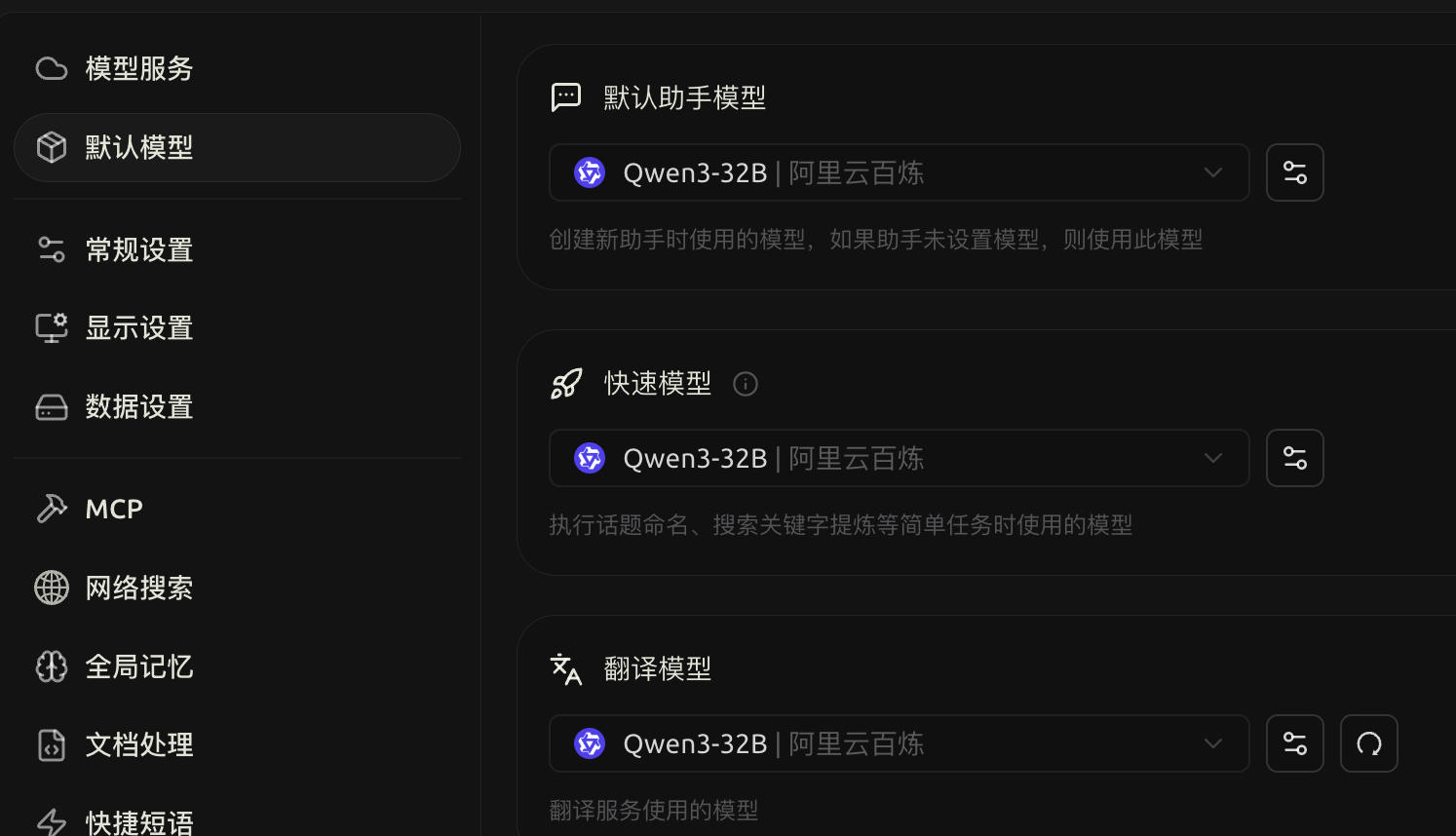
将三个默认模型全部设为Qwen3-32B,对于后面两个模型,需要修改一下提示词,在默认的提示词前面加上/no_think,避免模型过多思考影响效率。
切换到「助手」tab,右键「默认助手」,依次选择「编辑助手」->「模型设置」,然后将「工具调用方式」选择「函数」。
这里说明一下两种不同的工具调用方式有什么区别。
- 提示词
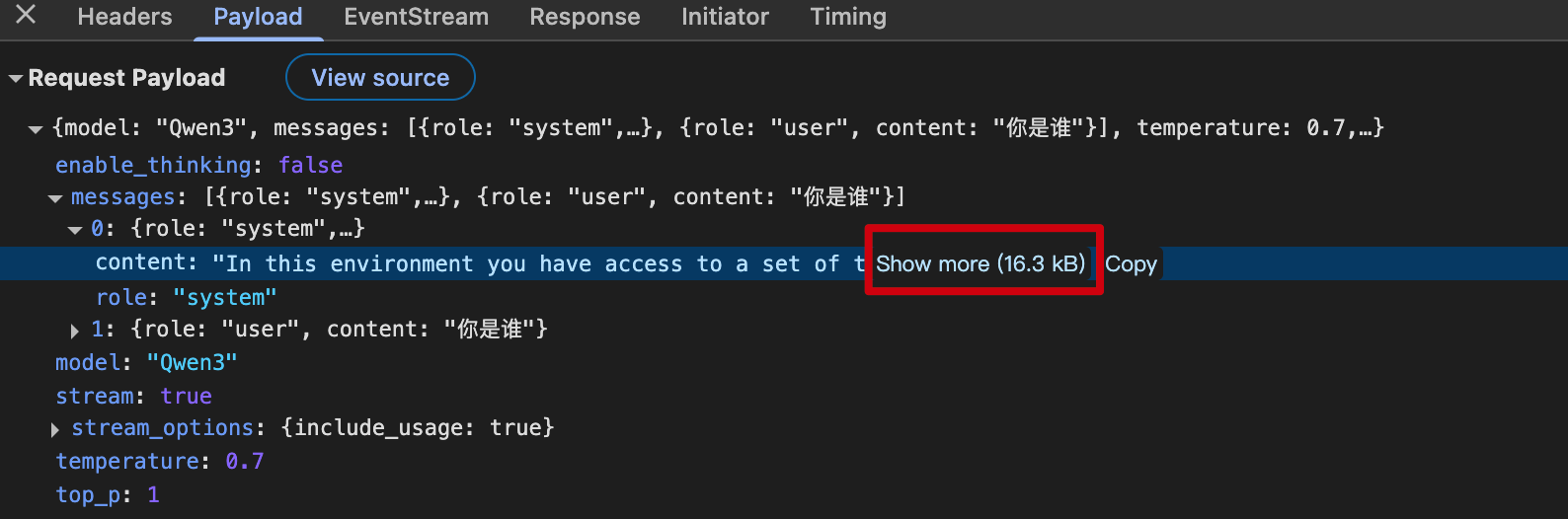
这个方式较为通用,是Cherry Studio为了让所有语言模型都能够调用工具实现的功能,通过在系统提示词中临时教模型如何使用工具来实现这个功能。通过提示词方式调用工具有个很大的问题在于系统提示词会非常非常长:”In this environment you have access to a set of…”,详见下图:
- 函数
在payload中添加一个参数:tools,将工具列表传入模型服务。这种方式需要模型具备function call能力,其请求如下图:
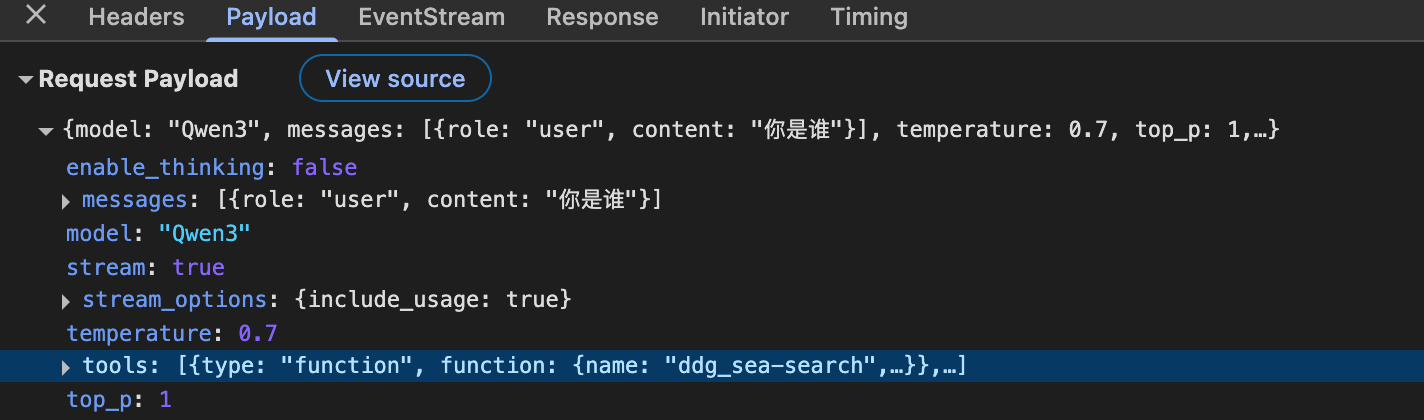
而Qwen3系列模型都具备function call能力,因此这一项勾选「函数」比较好,就别傻愣傻愣的每次都教它一遍了。
配置嵌入模型和重排模型
有时候我们会用到嵌入、重排功能,比如在使用知识库、搜索网页的时候。我们可以使用硅基流动提供的免费模型:
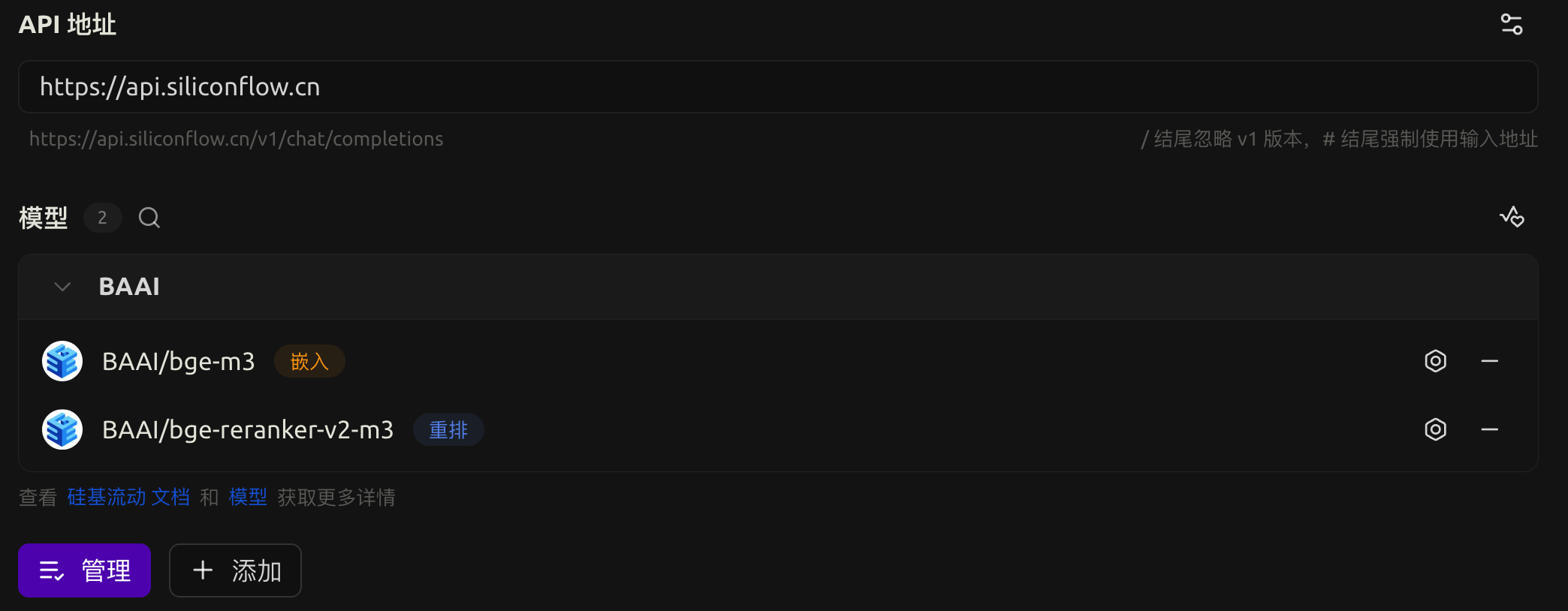
配置知识库
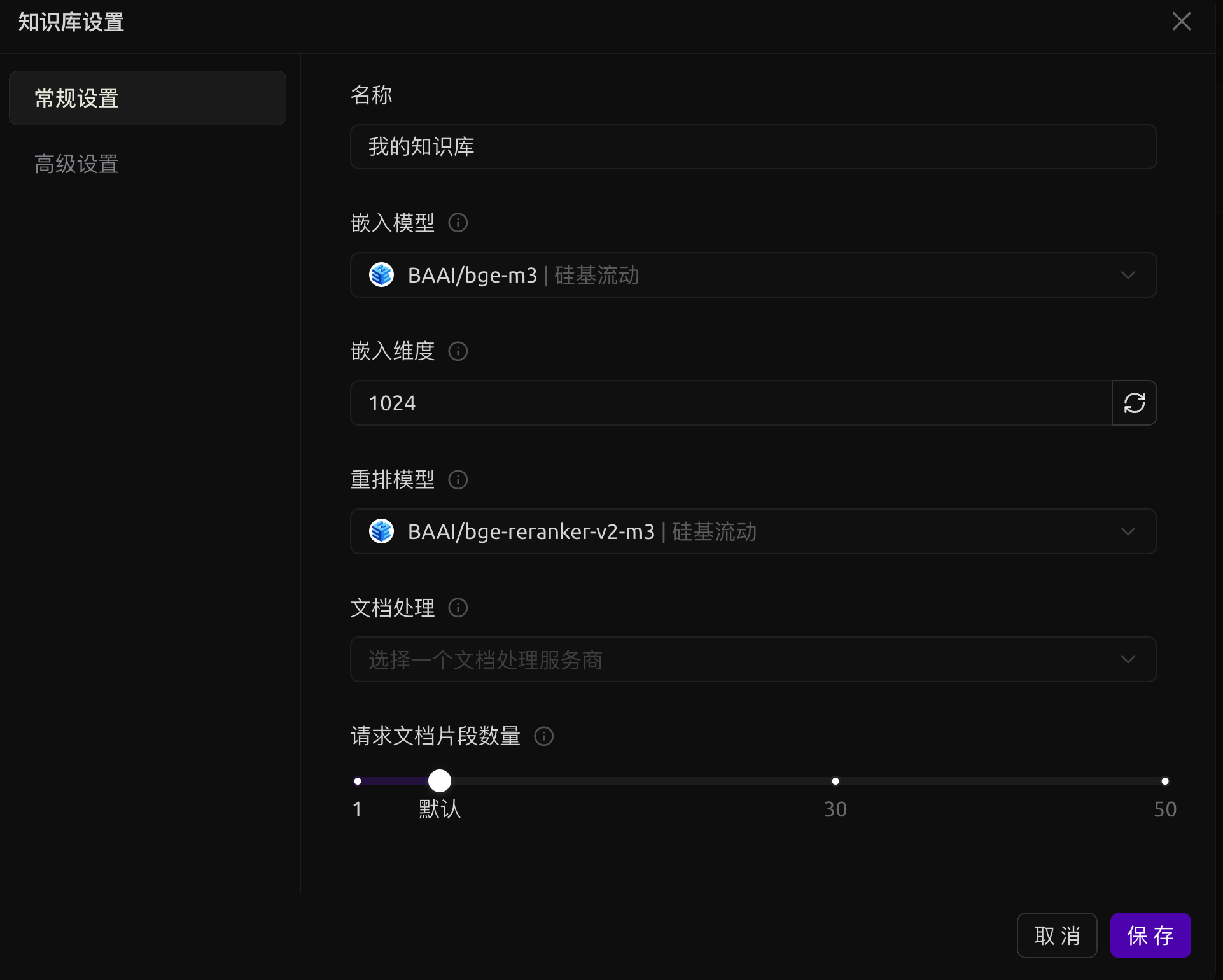
配置网络搜索
由于我的服务器性能不大行,只能跑得起5万token的上下文,因此在网络搜索的时候要尽可能减少传过去的内容。
于是,在网络搜索这里我用了RAG方法对搜索结果进行了一定程度的精简。
除了上面这些之外,Cherry Studio还提供了一个插件:划词助手,这插件是真的好用,支持基于大模型的翻译、解释、总结、润色优化等功能,你甚至可以在系统上任何能够划词的软件上打开它:
以上就是我使用Cherry Studio的一部分操作和配置,这款软件还有更多有实用价值、高自由度的功能(例如丰富的MCP工具)等待体验。
- V me 50!
- Alipay is also ok~





